Introduction
I show how to transpile, manually, a simple state machine diagram to Javascript code.
This essay tries to communicate the very fundamentals of this approach — State Machines and layers — aka Divide&Conquer on steroids.
I will discuss deeper issues in other essays.
Code Repo
The code for these examples can be found in
https://github.com/guitarvydas/example/tree/youtube
Video
https://www.youtube.com/watch?v=7YBKWwC2-Ww&list=PLVDkQ9A0-G_tLGQ3lbYxAJk_RFkCndu7a
Simple State Diagram
Fig. 1 shows the (simple) state machine used in this example.
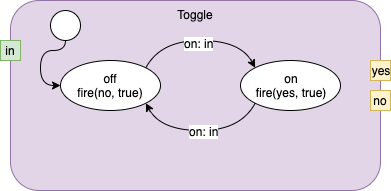
Fig. 1 Simple 2-state State Machine
Component Overview Layer
Name
The name of the Component is "Toggle".
Inputs
The Component has 1 input:
- in
Outputs
The Component has 2 outputs:
- no
- yes
State Machine Overview Layer
Currently, the Component is implemented as a State Machine.
The fact that this Component is implemented as a State Machine is only known by the IDE.
The implementation of a Component cannot be determined by the Layer 0 diagram. This detail is left to the IDE. The IDE knows how to read Component Implementations (in this case Layer 1).
The emphasis is on need-to-know layers. The diagram (layer 0) does not need to know how Components are implemented. The compiler does need to know this information. We defer providing this information and push this kind of detail as far down the stack of layers as possible.
Note that code snippets on the diagram are just strings. The diagram editor does not care what is inside of the strings. The programmer/architect/engineer must send the transpiled code+strings to an appropriate compiler/interpreter/REPL. At first, we manage this kind of detail manually. Later, scripts could be written to add automation to the process. It is important to perform all steps of the process manually at first (before adding automation), so that the process, itself, can be "debugged" and fleshed out. The only way to show that a process is complete is to show each step of the process manually first.[1]
The first rule of Divide & Conquer is to defer information until the last possible instant of time.
States
This machine has two states:
- off
- on.
Code Layers
Outermost layer
function Toggle () {
this.state = …
this.step = function (event) { … }
this.enter = function (next_state) { … }
}
At the outermost layer, the diagram transpiles into a block of code that
- creates a state variable
- creates a step funtion
- creates an entry function for each state.
Default State
function Toggle () {
this.state = _off;
this.step = function (event) { … }
this.enter = function (next_state) { … }
}
At the this layer, the diagram initializes that default state.
I've arbitrarily chosen the name "_off" to signify the state name.
I've arbitrarily chosen to represent states are integer constants. I could have used strings (say), but then I wouldn't be able to use Javascript's switch statement, later. What I really wanted is syntactic sugar for case-ing on strings.
Step Function
this.step = function (event) {
switch (this.state) {
case _off:
...
break;
case _on:
...
break;
default:
...
}
}
At this layer, we transpile the code for the state-machine step.
It shows that we case on the state variable.
In production versions, we can choose what happens in the default case — e.g. what happens when the machine is in neither of the case-ed states. Is this an error? (probably). Is this ignored?
The choice depends on the actual problem — in some cases, we want to build state machines that deal only with certain states and in other cases, we want this to be an error.
There is no one way to define this behaviour.
Entry Functions
this.enter = function (next_state) {
switch (next_state) {
case _off:
fire (_no, true);
this.state = _off;
break;
case _on:
fire (_yes, true);
this.state = _on;
break;
}
}
At this layer, we transpile (add in) the code for event-case-ing.
The machine breaks down into:
- examine the state
- examine the incoming event.
In production versions, we can choose what happens in the default case — e.g. what happens when the machine is not waiting for certain events. Is this an error? (probably). Is this ignored?
The choice depends on the actual problem — in some cases, we want to build state machines that deal only with certain events and, in other cases, we want this to be an error.
There is no one way to define this behaviour.
Completists might argue that all events must be handled in some way.
This is about utility, not completism — what features make it easier to architect/engineer/program the solution? [We don't throw information away, we just hide it, and make it more convenient to use].
The architect is responsible for making the design clear and readable to others.
Some problems are more clear if we elide details and some problems need to show all details.
For example, imagine the difference between writing an account-consolidation app versus writing a robot controller. The problems are different — and the expressions of the solutions are different.
For example, EEs do not draw schematics of the designs that show all of the details. They tend to elide +V and GND connections. EEs don't show the details of how chips are constructed (e.g. various layers of rust (oxides)) and so on.
For example, mechanical drawings often show three (3) views of the same object (front, top, side). This might be explained as a mapping from 3D space to 2D space.
Code is a mapping of computer operation through the dimension of time. In only some of the cases, e.g. for designing calculators and mathematical functions, does it make sense to elide the dimension of time. In other cases, e.g. the internet (networked computers), robots, etc., the dimension of time is important and must not be elided.
Knowing what to elide comes with experience in a given field.
Exit Functions
This example does not contain any exit code for states, but the code would be similar to that of entry functions.
Transition Functions
The transitions between states in this example, are coded into the step function.
It should be possible to move the transition code out into separate functions.
Transitions from one state to another, should:
- call exit code for the current state
- call transition code for the transition itself (code snippets associated with the arrow, instead of with the previous and new states).
- change the state variable of the state machine (to the new state)
- call entry code for the new state
- exit.
The sequencing of a transition in a HSM (hierarchical state machine) is similar, but contains more details, e.g. a recursive descent into the current state and calling exit code from deepest-child through all of its parents, and e.g. a recursive descent into the new state and calling entry code from parent to child at each layer, and, e.g. setting the state variable to a dynamic chain of sub-states instead of setting just a single, flat, state variable.
Next State
this.enter = function (next_state) {
switch (next_state) {
case _off:
fire (_no, true);
this.state = _off;
break;
case _on:
fire (_yes, true);
this.state = _on;
break;
}
}
In this example, I've chosen to set the next state in the entry functions, as shown above.
The next state could be encoded in a number of other places. Particularly, in a production version that uses HSMs (Hierarchical State Machines), the state variable would be changed as described in the Transition Functions section.
Note that it is possible to encode states and transitions in tables and to interpret the tables.
Code Snippets
At the lowest level, we insert code snippets, e.g. entry code specified as strings in the diagram:
function Toggle () {
this.state = _off;
this.step = function (event) {
switch (this.state) {
case _off:
switch (event.tag) {
case _in:
this.enter (_on);
break;
default:
throw "invalid input port";
}
break;
case _on:
switch (event.tag) {
case _in:
this.enter (_off);
break;
default:
throw "invalid input port";
}
break;
default:
throw "can't happen";
}
};
this.enter = function (next_state) {
switch (next_state) {
case _off:
fire (_no, true);
this.state = _off;
break;
case _on:
fire (_yes, true);
this.state = _on;
break;
}
}
}
Defer
This set of layers follows the convention of need-to-know (aka Divide & Conquer).
For example, none of the upper layers needs to know anything about the actual code snippets nor about the intended target language (e.g. Javascript, Python, Rust, etc.), so we keep code snippets in strings and insert them into the generated code as late as is possible.
Deferred Details Layer
Many details can be deferred until the very end of the transpilation process.
By deferring, I don't mean getting rid of, I simply mean pushing the details aside, pushing the details out of a given notation.
For example, the notation that we currently use for programming, elides the fact that CALL/RETURN uses a global stack. This is a convenient notation for a certain class of problems. It is an inconvenient notation for a different class of problems. Neither notation is usable for every kind of programming. Neither notation deletes the basic fact that the hardware uses a global variable — one notation hides this fact, another notation makes this fact explicit. For example, an accounting application makes makes certain calculations and translates these calculations into function calls that use the global stack in a synchronous manner. Another application, like an internet client client that request information from a server, cannot (easily) use the concept of a stack to describe asynchronous interaction with the server — the server does not act like a mathematical function, producing an output every time that it is sent a request (for example, it might produce a result, or, it might produce a timeout).
State Machine Name
I've chosen to represent the name of this simple state machine as
- a character string in the "name" line at layer 0
- an identifier used to name the function in the outermost layer.
State Names
This simple example has only two states "off" and "on".
I've chosen to represent the states as integer constants in the code.
I could have used some other representation. I considered using strings "…" but I knew that I was intending to use switch statements which don't allow strings.
In a larger, production project, I would let the transpiler emit state names.
To keep things architecturally generic, I would define an SCL[2] (aka DSL) that allowed me to use a "standard" notation, e.g. an identifier. I would write the transpiler (say, using a PEG parser, like Ohm-JS) and put my decision in the transpiler itself. For example, if I were emitting JavaScript, I would use strings, but if I were emitting C, I might use integer constants.
In the best of all worlds, I would design the transpiler so that it could generate code for any language.
Input Names
This simple example has one input port - "in".
The choice for naming input ports is the same as the discussion in the State Names section.
Output Names
This simple example has two output ports - "yes" and "no".
The choice for naming ports is the same as the discussion in the State Names section.
The decision for naming ports depends on the problem-at-hand. In some cases, we are willing to spend the extra design time required to use integers, and in some other cases, we don't care and strings suffice.
Deferred (Foreign) Functions
This simple example invokes one routine — fire() —to do work that is not specified by the diagram.[3]
This is another example of need-to-know design.
Most of the software layers do not need to understand the code contained in the deferred code snippets.
In this case, the text string code snippets represent Javascript function calls. The strings could contain Python code, Rust code, or erroneous code. The upper layers do not need to know this detail.
In the best of all worlds, I might choose to design a small language (an SCL)[4] for describing operations that appear in code snippets. In this way, I could defer the decision of which target language to use until (even) later, as long as the SCL generates code in my chosen target language.
The Drakon editor - http://drakon-editor.sourceforge.net/ - does something similar. It allows the architect (engineer, programmer, etc.) to draw diagrams and to defer the decision about which language will be emitted. The Drakon editor has a menu for selecting the target language. Code snippets in the Drakon editor are language-specific strings. If one writes snippets in one language, then tells Drakon to emit code in some other language, it will emit the code but the compiler will throw errors.
Kernel
We use a small library to enable operations in our State Machines.
I call this library the kernel.
In this case, the kernel is very small, consisting of one function:
function inject (component, event) {
component.step (event);
}
This kernel library function — inject — injects an event into to the state machine and then triggers the state machine into action.
In a production version, the library will be slightly larger. The main API of the library is:
function send (component, event) {…}
function inject (component, event) {…}
The send() function does mostly what the inject() function does, but assumes that the state machine is already running.[5]
In a production version, components will each have one input queue and one output queue and the kernel functions will enqueue and dequeue events.
In a production version of a system, components will be run by a single Dispatch() routine, breaking the synchronous behaviour of CALL/RETURN. This is discussed elsewhere.
Main
var top = new Toggle ();
inject (top, {tag: _in, value: true});
inject (top, {tag: _in, value: true});
inject (top, {tag: _in, value: true});
In the mainline routine, we need to perform the rituals, required by our target language, to cause the state machine to "run".
In this case the state machine is coded in Javascript. We need to
- Create an instance of the state machine
- Inject events into the state machine and observe the outputs on the terminal.
Execution
To execute the machine, in the code repo, we need to
- Strip the org-mode comments, leaving pure Javascript
- Invoke the javascript.
In this case, I have created a bash script that does both of the above. It is in
https://github.com/guitarvydas/example/blob/blog/run.bash
(github.com/guitarvydas/example branch "blog", file run.bash)
Compilation vs. Interpretation
It is possible to tune the implementation of state machines by transpiling the state diagrams into code or transpiling them into tables to be interpreted.
Everything is an interpreter.
Under normal circumstances, binary object code is interpreted by the hardware, e.g. using microcode.
Assembler is interpreted in two stages
- Convert the assembler source code into binary code
- Interpret the binary code using hardware.
Compilers are interpreters. They interpret code in multiple layers:
- Transpile source code to assembler.
- Convert assembler source code to binary code.
- Interpret binary code using hardware.
Likewise, type checkers — for example — are interpreters, too. They interpret type annotations and "simplify" the incoming source into assembler (binary). The "simplified" code is interpreted by the hardware and does not incur the cost of re-calculating types of certain data structures at runtime ("runtime" means: interpretation by hardware).
Compilers are interpreters. Compilers front-load certain checks and code sequences in the hope that such checks and sequences can be eliminated from the binary code, allowing for "more efficient" interpretation of the binary code by the hardware.
Likewise, state machines can be transpiled directly into binary, transpiled into assembler, transpiled into code for various languages (e.g. Javascript, Python, etc.) or transpiled into tables that are interpreted by underlying libraries (written in, say, Javascript, Python, etc.).
XState is a library that supports state machines (StateCharts, to be exact) in Javascript programs.
SCXML
SCXML is a specification of XML for StateCharts.
https://en.wikipedia.org/wiki/SCXML
StateCharts
I discuss Statecharts in
https://guitarvydas.github.io/2020/12/09/StateCharts.html
Basically, I think that the Statechart notation is too complicated.
I think that Statecharts can be broken down into two separate notations:
- HSM — Hierarchical State Machines
- Concurrency — Box-and-arrow diagrams, Arrowgrams, FBP, Bash, etc. (More on these issues in other blogs).
[1] This is a pet peeve of mine. It is often said that FP is a good way to write concurrent programs, but only toy examples are given. Trying to build full production systems results in a myriad of problems and overlooks the elephant in the room. For example, it is more informative to draw a network on a whiteboard than it is to describe a network using only text (I show that it is possible to transpile diagrams to code). Javascript's tortuous callback syntax is a result of this kind of stunted thinking (text-only, instead of using diagrams mixed with text). CPS is just GOTOs on steroids. Promises are based on threads, and threads are closures.
[2] SCL means Solution Centric Language. Similar to a DSL, but more focussed on the problem-at-hand.
[3] This idea comes from the S/SL language. See References on my blog https://guitarvydas.github.io/2021/01/14/References.html.
[4] SCL mean Solution Centric Language.
[5] Don't worry if this doesn't make sense yet. "Running" refers to the idea that there is a distinguished Dispatcher() meting out bits of control-flow time to closures. I will discuss this elsewhere.