Introduction
I describe the first four phases of converting an SVG diagram to code.
This example is very simple, but the technique has been used on large problems.
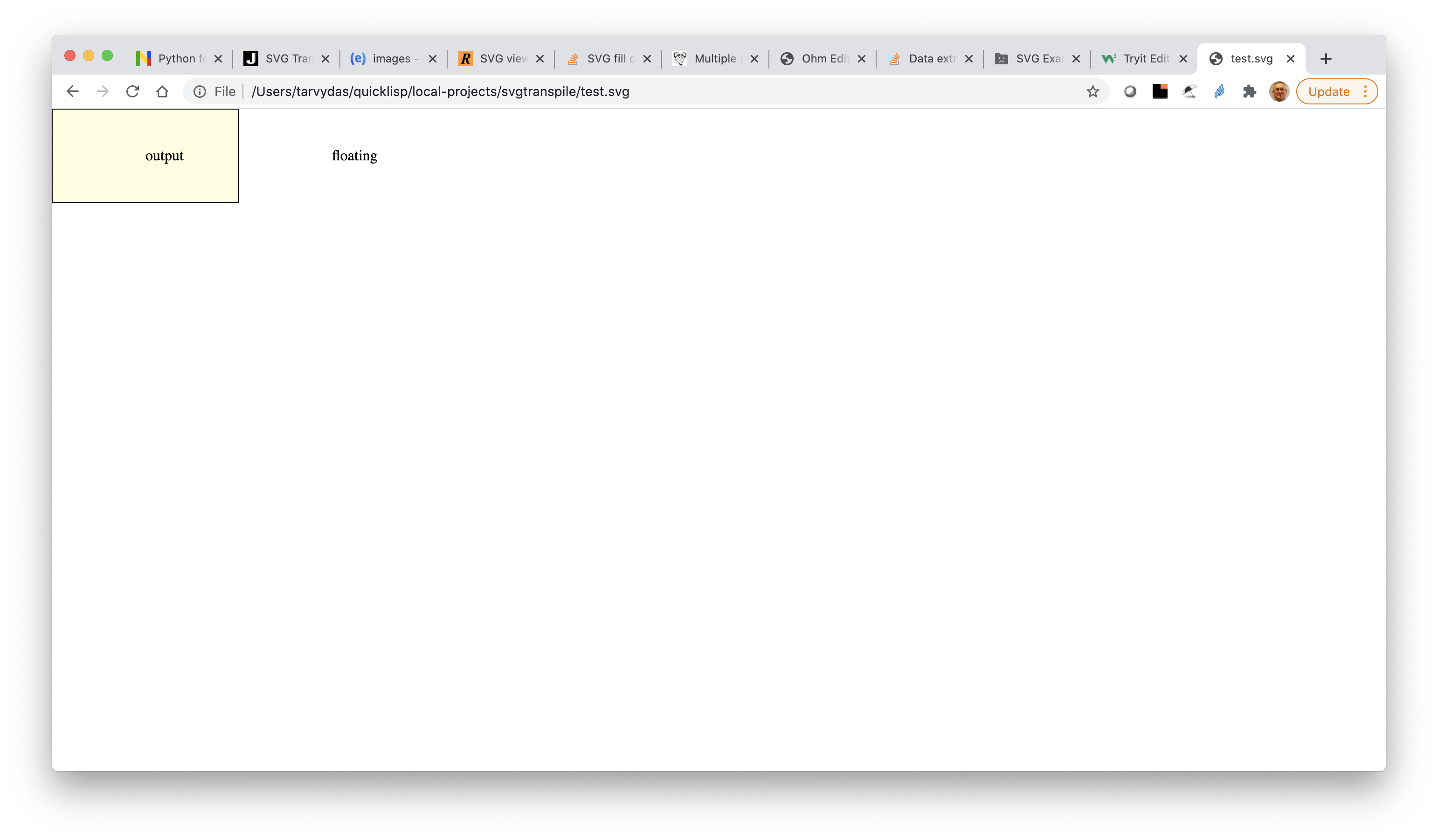
The example uses an SVG diagram containing one rect and two text elements.
I convert the diagram to PROLOG rules, using PEG. In this particular case I use a PEG to generate another PEG that forms a JavaScript program that outputs relations.
I use SWIPL to perform inferencing over the relations to output various results. One could use any language to do the inferencing[1].
I hope to show relations in a very basic form that needs no knowledge of PROLOG.
Github
The code for this essay can be found in
https://github.com/guitarvydas/svgtranspile
and the code for the PEG->PEG transpiler tool, called glue, is documented at:
https://guitarvydas.github.io/2021/03/18/Little-Language.html
(code for glue: https://github.com/guitarvydas/glue)
SVG File
The SVG used in this essay is:
<!DOCTYPE html>
<html>
<body>
<svg xmlns="http://www.w3.org/2000/svg" width="600" height="510">
<rect width="200" height="100" fill="lightyellow" style="stroke-width:1;stroke:black" ></rect>
<text x="100" y="55" fill="black">output</text>
<text x="300" y="55" fill="black">floating</text>
Sorry, your browser does not support inline SVG.
</svg>
</body>
</html>
When viewed in a browser, the SVG shows one rectangle (lightyellow) and two text fragments ("output" and "floating").
One text fragment — "output" — appears to be inside the rectangle. The other text fragment is not enclosed by any rectangle.
SVG to Factbase
The conversion from SVG to factbase format https://guitarvydas.github.io/2021/01/17/Factbases.html
is performed by using the glue tool.
This can be seen in run.bash.
The conversion is done in two steps (an arbitrary choice, but saves me time and maintains the DI[2]).
The steps require:
- a pattern for SVG files
- a specification of how to emit code for matches.
The SVG pattern is found in the file svg.ohm.
Typically, a pattern is fed into the Ohm-JS tool after which one writes JavaScript code[3] to do something with the resulting matches.
I chose to write another SCL (aka DSL) instead of writing raw JavaScript code manually. I let the SCL[4] write the JavaScript for me.
Basic Facts
The starting set of facts, gleaned from the SVG file, are:
fill
height_str
rect
svgbox
string
text
width_str
x_str
y_str.
The "…_str" facts remind me that values in the triples are strings, not numbers.
Strings to Numbers
As it stands, the factbase triples contain numeric data in the form of strings.
The file num.pl converts these strings into numbers.
Anti-Abstraction
The pattern actually over-specifies the SVG pattern matching, for example element is broken down as four basic matches, where it could have specified with only one match.
This is an idiom for using pattern-matchers — let the matcher supply the matching context. This is exactly the opposite of abstraction. I wrote redundant rules, letting the pattern matcher do more work for me.
Automation - Using Code to Write Code
You can create SCLs (DSLs) more easily if:
- You use PEG pattern matchers
- You make the output code very repetitive.
Code that is "not repetitive" creates edge-cases that need to be handled. Removing such edge-cases is vital to allowing quick construction of little languages — SCLs.
Imagine using a REGEX library in your favourite PL. REGEX is a DSL, but you rarely stop to think of it as a full-blown DSL, you just use it. REGEX's work well for line-oriented data with few "edge cases".
The ideal situation is to use pattern matchers like one uses REGEXs. Compiler technologies and DSLs have been steeped in mysticism, taking many months to build. PEG brings "compiler technology" into the realm of programming, taking only a day to build an SCL instead of taking months/years. The "tricks" for getting such rapid turn-around are the same as for REGEXs — don't try do to type-checking, don't accomodate many edge-cases. Let the underlying language handle type-checking. Get rid of edge-cases by looking for highly repetitive code sequences[5].
REGEX likes input that is arranged in lines of text.
PEG likes input that is arranged in nested blocks of text.
Patterns in REGEX are called REGEXs.
Patterns in PEG are called grammars.
I wrote a PEG pattern matcher for SVG and I wrote another PEG pattern matcher for my glue SCL.
The job of glue is straight-forward and has almost no edge-cases. The idea is that Ohm-JS needs a block of JavaScript functions — one function for each rule in the grammar. In this case, I needed code that would rearrange matching code bits and format them for output. JavaScript back-tick strings (and C format strings, and bash strings, etc.) would be enough to do the job, so I wrote a simple tool that created semantics JavaScript code for me, using JavaScript back-tick strings.
I have used Ohm-JS many times before. I knew that I would encounter simple formatting problems like this again, so the 1-day development effort was deemed acceptable. I would not have built this SCL if I knew that it would take some months or years.
My thinking has changed since I realized that I could cut development time down by about a factor of 10.
I cut corners — instead of automatically inserting the generated code into my Ohm-JS pattern matcher, I simply use my editor's COPY/PASTE function. In fact, I used the command-line cat program to paste the code into the Ohm-JS pattern matcher. If this was used very frequently, I would look at tools like m4 to help with COPY/PASTING[6]
DI
If you look at the generated code generated by the glue tool, all of the simplicity, of simply formatting the output, is hidden in a sea of JavaScript coding details.
The ideal of DI[7] is to show only what matters, eliding coding details. The specification of mapping SVG matches into formatted output is captured in the file svg2p.glue, while the rest of the details - JavaScript code - are deferred (and in this case, generated by a small tool).
svg2p
The specification for mapping SVG to formatted output is in file svg2p.glue.
For example, the first line:
htmlsvg [@ws docH htmlH bodyH @elements bodyE htmlE] = ${elements}
says that when an htmlsvg pattern is matched (see svg.ohm), it will have 7 sub-matches, named ws, docH, htmlH, bodyH, elements, bodyE and htmlE (resp.).
The spec says that ws and elements may contain multiple matches (i.e. these multiple-matches are returned by Ohm-JS in JavaScript arrays).
After the pattern-matching is finished, the matches in elements are simply printed out and the rest of the matches are ignored.
The right-hand-side of the "=" is taken to be a JavaScript back-tick string, in this case ${elements}.
The whole right-hand-side is wrapped with back-ticks and emitted as a JavaScript string, e.g.
return `${elements}`.
The glue tool also does some housekeeping for me and evaluates the sub-matches as required by Ohm-JS[8].
Hand-Optimization Urge
The formatted code, output by my use of the glue tool, is very repetitive.
Most programmers would not create such repetitive code and would feel compelled to "optimize" it, thereby, creating more edge-cases for formatting.
This urge-to-hand-optimize happened, also, during the transition from assembler programming to HLLs (like C and Pascal). Assembler programmers could not resist the urge to write "better" code. Compilers continued to emit very repetitive code, which was "worse" than that created by assembler programmers. Then gcc came along. Gcc optimized the repetitive code sequences and bettered most hand-written assembler code (at worst, it matched the "best" hand-written code). After that, few programmers bothered to write code in assembler any more¡.
[I view all current PLs as mere assembly languages and use PEG to build SCLs on top of them. Some PLs make "better" targets for automation than others https://guitarvydas.github.io/2021/03/16/Toolbox-Languages.html. It boils down to unnecessary edge-cases[9] and unnecessary syntactic sugar. In this essay, I treat JavaScript and PROLOG as assembler languages and automatically transpile code into their syntax. IMO, paradigms, such as OO and FP and relations, are often conflated with syntactic sugar. It is not possible to create a syntax that fits all use-cases. Paradigms and syntax should be treated orthogonally. Experimenting with paradigms is not the same as experimenting with syntax[10] https://guitarvydas.github.io/2020/12/09/Programming-Languages-Are-Skins.html]
Sorting
PROLOG requires that rules be clumped together.
UNIX® sort is enough to produce this clumping.
I leave the factbase unsorted for ease-of-reading. I call sort to create factbases for use with PROLOG.
Bounding Boxes
We want to "normalize" data so that it is easier to search.
To this end, we want all shapes to have the same form.
I have learned, through experience, that creating a bounding box for every shape is a useful normalization[11].
There are some shapes that do not fit the bounding-box model, notably lines. We'll treat lines differently. In this example, there are no lines at all, so — problem solved :-).
SVG specifies rects in (x,y,width,height) form.
A bounding box for rects would be (left,top,right,bottom) form, which means that we need to expand width and height in some way.
SVG text elements are specified only as (x,y). We would need to know the font-size and the string size of each string to create bounding boxes for text. This is not impossible to do, but we will avoid it in this example[12]. For now, we will not create bounding boxes for strings and will use only their (x,y) points. Later, we can decide if this approximation causes us problems.
So, we will create bounding boxes for rects (only). To do this, we are going to need to write code that converts (x,y,w,h) into (l,t,r,b), something like:
left = x
top = y
right = x + width
bottom = y + width
So, for every rect, we will need to lookup its (x,y,w,h) and create a new bounding-box fact that contains (l,t,r,b).
We store all information in normalized triple form, so we need to find all
rect(R,"")
x(R,X)
y(R,Y)
width(R,W)
height(R,H)
and convert this information into bounding box triples, such as
bbleft(R,X)
bbtop(R,Y)
bbright(R,X+W)
bbbottom(R,Y+H)
Obviously, we could use a loop or recursion to perform such searches an insertions. I have done this many times and have found that PROLOG gives me an easy way to write this kind of searching-and-inserting-code. I will use PROLOG[13].
Note: there is no need to optimize the contents of the factbase. We can just keep adding facts to the factbase. Defer optimization until later (I have done this many times and have never needed to optimize the factbase — a demonstration of the power of procrastination!). The searching algorithms simply skip over unneeded facts.
In fact, the above pseudo-code is almost PROLOG. I need to add comma (instead of semi-colons as in some other language) to the end of phrases and, I need to check that PROLOG variables are written beginning with upper-case letters and everything else is written beginning with lower-case letters[14]. The end of each rule needs to end with a period (.).
The resulting code can be seen in bb.pl and it is executed in run.bash.
Names for Rects
Next, we want to assign names to every rect.
Every text element contains text and we will simply look for text (x,y)s that are inside rectangles.
In my expected use-case for this kind of diagram, I will have big rectangles that represent software components and smaller rectangles that represent ports for the components (coloured palegreen for input ports and lightyellow for output ports).
All ports and all components will have a name.
We will use a simple check to determine names for rects — "is the (x,y) of the text enclosed in the (l,t,r,b) of the rect?".
This simple check makes it possible that one text element will be inside more than one rectangle, e.g. a port name inside the port and inside the component. To ensure that we don't map the same name to a port and its component, we will use the simple rule that a text matches with only the smallest rect that can be found. This check might not be enough, but it will suffice for this example and will show the general gist of how to build PLs based on DaS[15].
The code for finding such matches is in names.pl. See, also run.bash, for how to execute this code and append its output to the factbase.
Design Rule Check (Example)
At various points in the workflow, we will want to throw-in various design rule checks.
Existing, text-based PLs, tend to do all of the checks at once.
This is called "type checking", "semantic analysis", etc.
In our case, we are creating a workflow that is a pipeline of fact-creators that ends with code formatters. We can add checks at any point in the workflow.
As (only) one example of this kind of checking, I've built a filter that checks for floating text — text that is not enclosed in any rect.
The code for this one design rule checker is in uncontainednames.pl.
We would want to add more checks to create a more useful version of this example.
Again, see run.bash, to see how I decided to run the checker.
[1] e.g. Scheme, JavaScript using loops-within-loops or with my js-prolog library https://github.com/guitarvydas/js-prolog, or any other language.
[2] DI means Design Intent (often called Architecture).
[3] Called the "semantics".
[4] I call the SCL tool "glue".
[5] This is what compiler-writers do. They generate "some" code, then "optimize" it with other tools.
[6] In fact, m4 does a lot of what OO is meant for. I haven't tried, but I think that m4 could be used to implement Bennett's Frames.
[7] DI is Design Intent.
[8] All of this emits JavaSCript code.
[9] e.g. declaration before use
[10] This is another instance of fractal-thinking. What we generally consider to be PLs, can be broken down into two sub-components - paradigm and syntax.
[11] YMMV
[12] For example, a reasonable first approximation imight be to assume that all text is in 12-point font. We won't deal with this problem in this example and will defer it to later.
[13] You don't have to use PROLOG, if you don't want to.
[14] The pseudo-code is already written that way.
[15] DaS means Disagrams as Syntax.