In this essay, I discuss a simple problem and its FDD workflow and tools.
The problem is that of gathering bank/credit card/expense statements and producing a single trial balance in .CSV format.
Programming breaks down, broadly, into two phases:
I will discuss this breakdown in more detail.
[In another essay, I call these two phases “breathe in” and “breathe out” https://guitarvydas.github.io/2021/03/18/TOE-for-Software-Development.html]
In the gather phase, we collect and parse information.
Ideally, we want to gather information and convert it into a single format.
I.E. we want to normalize the data.
We want to capture information in small phrases.
In the output phase, we want to re-arrange captured data and surround it by extra text as appropriate.
Some of the output will be in textual form and some will be in the form of control information1.
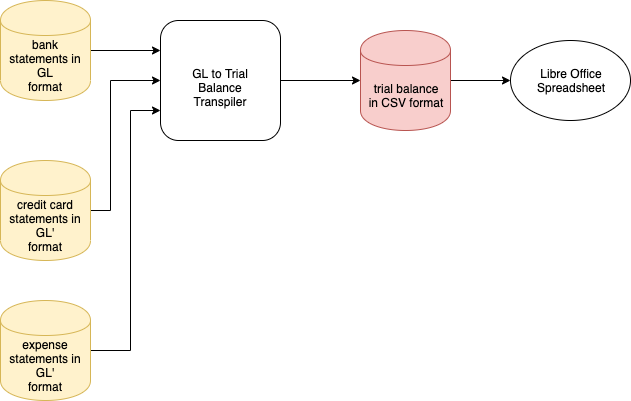
An overview of the system is found in Fig. 1.
Fig. 1 Overview
We have three input files (yellow) and generate an output file (red) in spreadsheet format.
The overview is fairly simple.
That is the intention.
Goal: Simplicity all-the-way-down, if possible.
This goal is kept in mind and drives choices in the design process.
The “API” for the input files is: structured text.
The “API” for the output file is: spreadsheet format (.CSV text file).
Details are deferred to lower layers. The sub-goal is to maintain simplicity at all levels of the design — using automation, but automating processing of very simple formats. Building up type information using layers instead of using a one-fell-swoop-style type-checker commonly found in most PLs.2
[A key point to notice is that we do not assume a 1–2 breakdown — input format vs. typed API format. We will use multiple layers and try to keep each layer “simple”3 (yet fully typed).]
IMO, typing is over-rated.
The real measure is ease-of-understanding.
Complex type systems are needed in languages that do not allow all solution code to fit in one small window.
An answer to this problem is to create layers of code. Each layer is made to be simple enough and to be stand-alone and to fit in one screen.
This may seem to be facile solution, but, it is not easy to devise a way to layer code so that each layer remains simple.
In a layered system, where each layer is understandable in a stand-alone manner, automated typing becomes less of an issue.
BASIC, et al, tried to use relaxed typing, but failed when programs became too large to fit in a small window.
Layering allows us to create simple-enough layers while making the typing “obvious” (or easily checked by automation).
One might think of type-checkers as part of the incremental loaders.
Each invocation of a loader type-checks the layer-in-question, but no more.
One might think of type-checking and loading as a recursive process - each step in the process whittles the problem down, and leaves “the rest” to other incremental loaders and incremental type-checkers in the pipeline.
[Actually, the pipeline is not a 1-D chain, but a tree of layers, each incrementally checkable. The most-final loader simply bolts together incrementally-type-checked pieces and finishes the left-over type-checking.]
In the gather phase, we collect and parse information.
Ideally, we want to gather information and convert it into a single format.
I.E. we want to normalize the data.
As a first attempt at normalization, I would suggest the use of factbases. https://guitarvydas.github.io/2021/01/17/Factbases.html and https://guitarvydas.github.io/2021/04/26/Factbases-101.html
Normalizing data means to convert all data into a common format.
I favour the use of factbases4 for normalization.
Further discussion of factbases can be found at https://guitarvydas.github.io/2021/01/17/Factbases.html.
Another simple normalized data format is text.
The UNIX® tools achieved much of their utility from the fact that all input and output consisted of lines of text.
The UNIX® tools worked with lines of text but became hard-to-use when the text was structured in some manner (e.g. scoped programming languages).
Parsing technologies, such as PEG parsing, are a way to parse lightly-structured text.
Note that lines of text and PEG-parsable text are very simple in format — i.e. they have little semantic content.
Type-checking and other forms of checking for semantic content is missing from the lowest levels of UNIX® tools.
Type checking can be added incrementally by inserting filters into the text-to-text pipelines.
Type-checking can be done on an as-needed basis, by cascading a number of filters between the source and the destination ports of components.
Software based on APIs is hard to bolt-together because APIs contain too much detail. This information is not discarded but is elided and deferred to filters.
In this simple example, we want to convert general ledgers (GLs) from text format to spreadsheet format.
Our intended output format is anything that fits in a spreadsheet cell, e.g. numbers, currency, dates, strings, booleans, etc.
Outputting can be quite simple.
I would suggest the use of Javascript back-tick syntax (which appears to have been inspired by /bin/sh, etc.).
The utility of using only back-tick syntax can be seen in the Glue tool https://guitarvydas.github.io/2021/04/11/Glue-Tool.html (and the follow-on Grasem tool https://guitarvydas.github.io/2021/04/11/Grasem.html).
I show an example of using the back-tick notation to perform real work, in 3 essays: https://guitarvydas.github.io/2021/04/12/Recursive-Iterative-Design-By-Example.html and https://guitarvydas.github.io/2021/04/20/Recursive-Design,-Iterative-Design-By-Example-(2).html and https://guitarvydas.github.io/2021/04/26/Recursive-Design,-Iterative-Design-By-Example-(3).html).
Javascript’s back-tick notation is capable of calling functions and other complicated behaviours. It appears that the majority of use-cases simply need the text substitution capabilities of back-tick notation.
E.G. to control a machine, a robot, a device, etc. ↩︎
PL means Programming Language. ↩︎
E.G. simple format is (1) factbases, or, (2) flat text, or, (3) structured text which is parsable using automation (e.g. with PEG). ↩︎
Further discussion at https://guitarvydas.github.io/2021/01/17/Factbases.html. ↩︎