What If?
What if it was easy to create compilers and languages?
Say, 10 minutes instead of several years?
How would your approach to programming change?
Does your favourite programming language have REGEX built in? Or, does it have a REGEX library?
What if writing a new language, a new DSL, were as easy as writing a REGEX?
Paradigms, Not Languages
Paradigms, e.g. OO, FP, message-passing, etc. would still be important.
Languages and syntax would no longer be important, if you could build languages as easily as writing REGEXs.
You could easily wrap a language around any given paradigm.
If you didn't like a particular language, you would throw it away and build a new one to suit your needs (10 minutes, not years) .
A Language for Every Problem
If languages were cheap to build, you could build a new language every time you started a project.
This would be different, even, from creating DSLs.
Normally, we think of DSLs as being tied to particular technologies, like SQL is a DSL for database queries.
Instead, we could just invent a DSL for every project. For example, if we used a database for Project XYZ, we could have a XYZ-DSL for the project. It would generate SQL queries based on what the Project XYZ needed.
XYZ-DSL would not be general. It would be specific only to project XYZ.
We already do that, when we build code in a programming language, but we don't separate the code details from the architectural needs of the project.
The code to solve a problem is like a custom-fitted DSL for solving the problem. From a maintenance perspective, it is just as "hard" to learn what the code is doing as it is to learn a DSL geared for the problem. Actually, it might be easier to understand a solution if only the meat was shown, less all of the nitty-gritty details of how the details were force-fitted into a chosen language (or DSL).
We use a language, and a DSL, which is sufficiently general, then we write code in that language until we solve the XYZ problem. By using an existing language, we use a notation that is specific to some other problem — not the problem-at-hand.
Sometimes, we don't need all to use all of the fancy features of a language.
Sometimes, the details (is this a list?, is this an array?, is this an int?, is this a double?, etc.) obscure the real meat of the solution.
REGEX
REGEX is a simple DSL.
REGEX was, originally, compiler technology.
Today, it is possible for non-specialists to use REGEX.
What can REGEX do?
- It can match strings.
What can't REGEX do?
- It can't match nested strings.
- It can't match across lines.
Is there something that can do what REGEX can do and what REGEX can't do?
Yes.
PEG.[1]
Is it built into other languages?
- No,[2] not yet.
SCNs - Little DSLs
I use the mnemonic SCN — Solution Centric Notation — to mean little DSLs that are specific to a solution.
Pipelines Instead of Hacking
What if we could just leave well-enough alone?
What if, when a piece of software works, we leave it alone?
When we hack on a piece of already-working software, we often get unintended consequences.
Hidden dependencies cause unintended consequences.
FP[3] attempts to alleviate unintended consequences.
But, we already had this problem licked in the 1970's without all of the restrictions imposed by FP.
What we really want is called isolation.
UNIX®, for one, gave us isolation (in the form of processes and pipes).
Running FP on top of Linux is over-kill, from the above perspective.
Management Hates DSLs
Management hates DSLs because of the feeling that DSLs take a long time to build (years instead of 10's of minutes).
Management doesn't notice that it takes a long time to understand a production program.
This time would be reduced (or, worst case, be the same) if the program were well-documented.
Documentation Doesn't Work
Documentation "doesn't work", because it goes out of date, because it is not automatically tied to the final code.
Can we repair this problem?
Efficiency
If N=10, O(N) is 10, O(N**2) is 100 and O(N**3) is 1000.
So what?
A human perceives a keystroke to be sluggish if it takes more than 20msec. to register.
The human user doesn't care about O(_) performance.
The human user only cares that it takes less than 20msec. per keystroke.
How many CPU cycles are needed for 20msec? What is N?
It depends.
The answer is different on a cheap rPi than on a modern MacBook.
Hardware Engineers perform worst-case analysis.
Programmers perform O(N) calculations.
Most programmers don't even know what the latency of Linux is on the target hardware (nor on their own development system).
Using Rust isn't going to speed up Linux context switches.
How many context switches happen when a customer pushes a key or clicks a mouse button?
What is the cost of using a thread?
What is the cost of a function call?
Data Structures
There is only one data structure: the triple.
Everything else can be reconstructed from triples.
Building data structures at compile-time is an optimization, developed at a time when CPUs and Memory were expensive.
https://guitarvydas.github.io/2021/01/17/Factbases.html
https://guitarvydas.github.io/2021/03/16/Triples.html
Many apps run on modern hardware, where CPUs don't need to be time-shared and we are not allowed to think of memory sharing.
Data structure building at compile-time is but an optimization.
Do we need such optimizations? Should we pay for such optimizations with time spent in development?
The answer to these questions depends on what the final hardware will be. Developing such optimizations in an app should be performed by Software Optimization Engineers, not Software Architects.
Are we paying for such optimizations? Yes — these optimizations bring baggage that we call "thread safety", "full preemption", etc.
Do we need these optimizations in every app? Only a few apps need to worry about time-sharing, e.g. Linux, Windows, MacOS, etc. Running Linux on rPis means that we are putting these optimizations into every app that we run on the rPi, regardless of whether we actually need time-sharing and memory sharing in the app.
Could we approach apps differently and do away with the above accidental complexities? Anonymous functions (aka closures) do a lot of what operating systems do, but at a much lower cost.
How To Improve Programmer Efficiency
Improving programmer efficiency is different from improving program efficiency.
Early Lisps were geared towards improving programmer efficiency, with concepts like the REPL, built-in debugging,[4] debuggers[5], etc. Some of this programmer-efficiency attitude was lost when CL was standardized (CL includes features that make Lisp easier to compile[sic], which tend towards eroding debugability).
We know that comments don't work, because they go out of date, because they are not automatically connected to the code. When the code changes, one has to remember to change the comments. When delivery deadlines loom, comment improvement suffers.
The solution is to automatically tie comments to code and to make comments "write the code" — no change to the system can be made without changing the comments. (N.B. this also means prohibiting round-trip — the comments must be the only way to change the code).
Can this be done? I think that SCNs[6] can serve in this capacity at almost no increase in cost. Capture the thinking in an SCN, have the SCN generate executable code.
Rebol programmers love Rebol because of its similarity in this regard — Rebol dialects capture thinking as SCNs that hide details from dialect users. Rebol users see pure utility, containing very little noise.
Appendix - Ohm Editor
I debugged a lot of grammars manually. Most of them were recursive-descent grammars (often written in S/SL).
Grammars made hard problems easier to solve.
Debugging grammars generally took about a day or two.
The Ohm Editor — https://ohmlang.github.io/editor/ — is an IDE for debugging grammars. Grammar debugging is about an order of magnitude faster with the Ohm Editor (compared to debugging grammars manually, using generate-compile-edit-test cycles).
The Ohm Editor is useful for any PEG, although it has slight syntactic differences. I believe that using the Ohm Editor for developing a non-Ohm PEG grammar is faster than trying to develop the grammar in the usual way. The major difference between Ohm and other PEGs, is Ohm's treatment of upper-case vs. lower-case grammar names. This difference can be easily overcome by using lower-case names for all PEG rules. (There are, then, minor syntactic differences, but they are minor, e.g. "=" instead of ":" for rule definition, and so on) .
Ohm Editor Introduction
A screenshot of the Ohm Editor is show in Fig. 1.
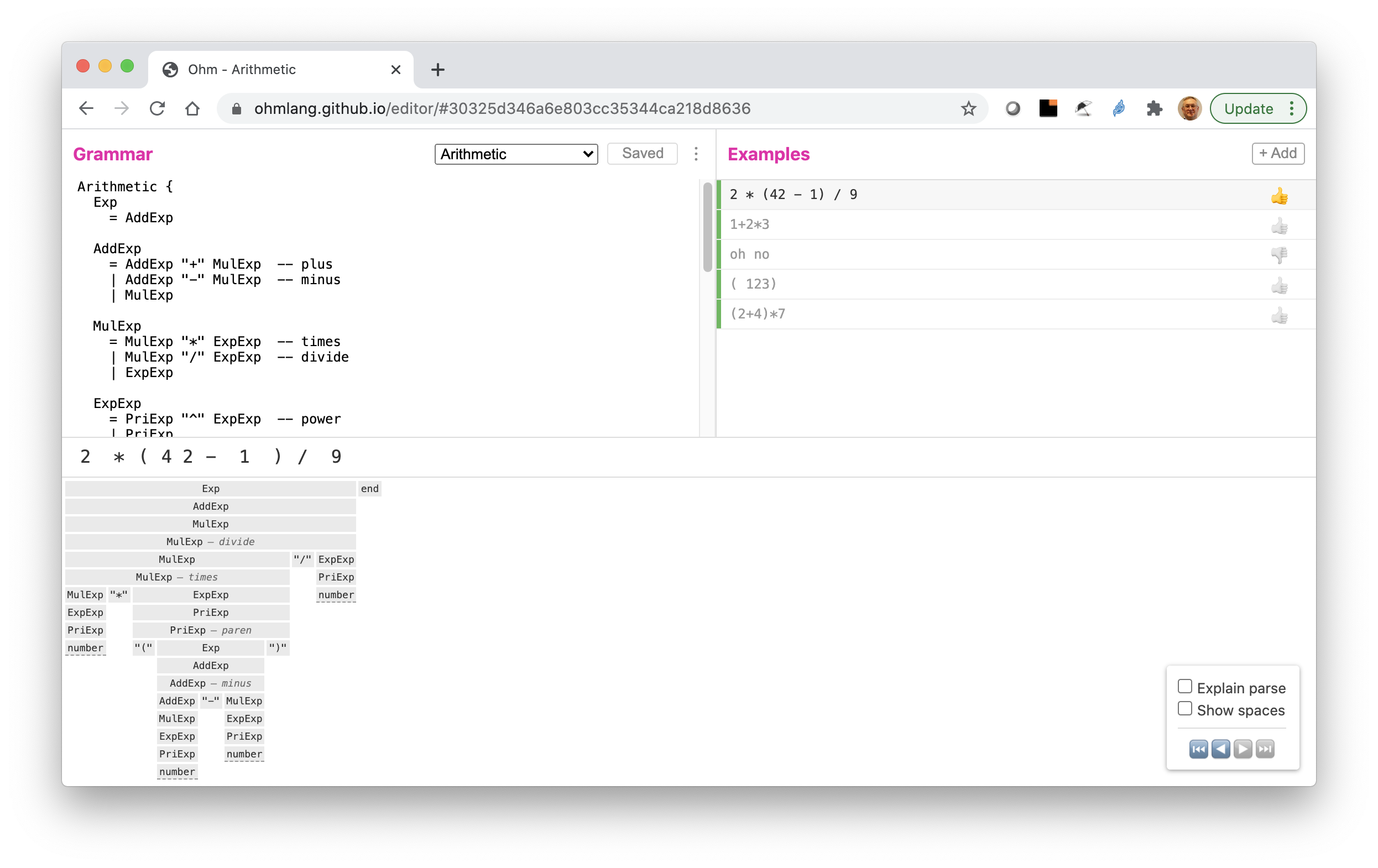
Fig. 1 Ohm Editor screenshot.
The screen is divided into 4 sections — upper left, upper right, the middle and the bottom.
The upper left section holds the grammar under development.
The upper right section hold various test cases. Test cases can be add using the "+Add" button or by double-clicking on a specific case.
The middle section (here showing "2 * * 4 2 - 1 ) / 9") shows the string being parsed.
The bottom section shows the resulting CST[7]. The CST is gray when the parse is successful and red when the parse fails. Hovering over a node in the parse tree highlights the corresponding grammar rule.
The most common problem encountered when debugging a PEG grammar is the that of incorrect parsing of whitespace. The Ohm Editor lets you see what the parser is doing and can give you hints as to where the parse is failing.
Appendix - Thoughts About PEG in Editors
REGEX is found in many editors, namely Vim and Emacs.
Q: How could we wire PEG into editors? The main difference between PEG and REGEX is in the number of lines for a specification. REGEXs are usually one line long and PEG specifications are usually many lines long. Awk faced this same issue when compared with grep and sed.
Ohm-JS works inside of HTML. (See the Ohm documentation for further details)
Appendix - Other Languages with PEG
Racket
#lang peg
or
(require peg)
REBOL
REBOL's parse is PEG or very much like PEG.
https://en.wikipedia.org/wiki/Rebol
Lisp Macros
Lisp macros are not PEG, but they show what can be done if you build a language that is machine-readable (vs. human-readable).
[1] Actually, other parser technologies like ANTRL do this. PEG feels more "light weight" to me.
[2] There is Rebol and its Parse function. There is #lang peg in Racket. There seems to be no Perl for PEG, though. REGEXs are built-into JS and Python. Can PEG be built into those languages?
[3] FP is Functional Programming
[4] For example, CL defines BREAK as part of the language, etc.
[5] Lispworks has a better debugger than emacs (e.g. emacs+SBCL, etc.). They both appear to have the same features, but debugging flows more smoothly in LW.
[6] and PEG
[7] A CST is often called an AST. When fractalized, a grammar breaks down into two parts - the AST and the CST (abstract syntax tree and concrete syntax tree, resp.). The AST shows what can parsed, which the CST shows what was parsed (in concrete terms).