Introduction
In this essay, I show how to create a small language rapidly (in about one day).
Normal programming skills are required. One doesn't need to know compiler theory to build little languages in this way.
I believe that this method can be used to enable a new class of small languages that I call SCLs — Solution Centric Languages.
How - Overview
I use a PEG[1] parser — Ohm-JS.
I create an example program using the small language.
I transpile the example program into JavaScript. I expect that the transpiler could be tweaked to emit code in just about any current PL (Programming Language).
I defer many details, in the hopes of clarifying the underlying methods.
I defer most checking (type checking, etc.) to the underlying language (in this case JavaScript), although checking could be performed by adding small amounts of effort and code.
Github
The code for this example can be found at https://github.com/guitarvydas/sm/tree/master.
Other References
I created other documents and videos as I built this particular transpiler.
For a summary of the method, see:
https://guitarvydas.github.io/2021/02/26/State-Machines-to-JavaScript.html
For a screencast record of the actual development process (including mistakes and backtracking), see
Syntax
IMO there is no reason to restrict oneself to using only textual representations for creating languages and little languages (SCLs).
Diagrams express networks better than text.
Diagrams express composition better than text.
Text expresses mathematical functions better than diagrams.
Text expresses mathematical operations better than diagrams.
Diagrams express certain kinds of control flow better than text.
Text expresses one-in-one-out functions well.
Diagrams express one-in-many-out functions better than text.
Text does not express M-in-zero-out or zero-in-N-out functionality well.
Future
I expect to show:
- how to build a stack-based[2] small language for building a transpiler and to show how it fits in with PEG parsing and Ohm-JS
- how to transpile an SVG diagram to JavaScript (the SVG source is treated as a little language that transpiles to a state machine little language that transpiles to JavaScript).
Need to Know - Defer, Defer, Defer
I argue that details are the bane of PLs.[3]
Most PLs (Programming Languages) require too many details and elide very little.
I do not advocate removing details, but I do advocate eliding details.
Which details need to be elided depends on the problem-at-hand and cannot be generalized.
I advocate building software in layers, like the acetates used to make cartoons at Disney.
Each layer of software does only one thing.
This attitude can be seen in the design of this little language — SCL. This little language deals with transpiling state machines into control flow, e.g. switch statements — and leaves all other details, like type-checking to other software layers.
Most current PLs provide only a single layer — and drown the user / reader in a sea of details.
If the language you use provides, say, a "+" operator, then it requires too much detail.
I advocate making the DI (Design Intent) clear to the reader. My thoughts on DI can be found in my essays at https://guitarvydas.github.io/.
To achieve my recommended level of layering, one should try to defer as much as possible. Each layer should be built on the need to know principle, i.e. if the information is not needed at a certain layer, then leave that information aside and use the minimum little language that allows you to express the DI at that layer.
Steps for Creating a Little Language
- Mock up the language
- Write a grammar
- Test the grammar
- Run the grammar
- Emit JS code (semantics)
- Run the transpiler
- Iterate
Realization
- Mock up the language
- Write a grammar
- Test the grammar
- Run the grammar
- Emit JS code (semantics)
- Run the transpiler
- Iterate
Mock up the SCL
[I show how to create the SCL in https://guitarvydas.github.io/2021/02/26/State-Machines-to-JavaScript.html]
The mockup emulates Fig. 1.
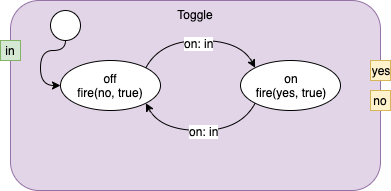
Fig. 1 Simple 2-state State Machine
The corresponding text version of this diagram is:
name:
Toggle
inputs:
_in
outputs:
_no
_yes
machine Toggle:
state _off:
entry: "fire (_no, true);"
on _in : next _on
state _on:
entry: "fire (_yes, true);"
on _in : next _off
default: _off
end machine
Of note is the fact that the SCL does not attempt to express everything.
StateChart diagrams are good for expressing control-flow, whereas textual code is good for expressing details such as function calls.
Specifically, the entry code represents deferred code as a string of characters. These characters are not processed by the SCL transpiler and are simply output to the final result.
The SCL creates only ten (10) keywords, namely:
- machine
- name
- inputs
- outputs
- end
- state
- entry
- on
- next
- default.
Everything else is left up to the base language. In this case, I will be using Javascript as the base language. It should be possible transpile to most PLs (Programming Languages).
In fact, if one were to design a separate SCL layer for expressing entry, exit and transition code, then the transpiler could be made to be language-independent.
In the above, the underscore "_" character is in no way special — it is simply a valid character for naming identifiers. I have used "_" as a way of distinguishing significant identifiers, such as state names, inputs and outputs.
Write a Grammar
I used the Ohm Editor to help write and test the grammar.
The Ohm Editor is found at https://ohmlang.github.io/editor/.
The grammar is
SM {
Main = StateMachine
StateMachine = NameSection InputSection OutputSection MachineSection
NameSection = "name" ":" Name
InputSection = "inputs" ":" InputPinNames
OutputSection = "outputs" ":" OutputPinNames
MachineSection = Header State+ Default Trailer
Header = "machine" MachineName ":"
Trailer = "end" "machine"
Default = "default" ":" Name
State = "state" StateName ":" EntrySection Transition*
EntrySection = "entry" ":" string
Transition = "on" Name ":" "next" Name
keyword = "machine" | "name" | "inputs" | "outputs" | "end" | "state" | "entry" | "on" | "next" | "default"
InputPinNames = nameList
OutputPinNames = nameList
MachineName = Name
StateName = Name
InputPinReference = Name
StateReference = Name
Name = ~keyword id
nameList = (~keyword id delim)+
id = firstId followId*
firstId = "A".."Z" | "a".."z" | "_"
followId = firstId
string = "\"" stringChar* "\""
stringChar =
escapedChar
| anyStringChar
escapedChar = "\\" any
anyStringChar = ~"\"" any
delim = (" " | "\t" | "\n")+
}
Ohm Editor Usage
The Ohm Editor is found at https://ohmlang.github.io/editor/.
It consists of three (3) windows (divs):
- grammar (top left)
- examples (top right)
- parse (bottom) - consisting of a single line (the test code) and a larger div showing the resulting parse tree.
Enter the grammar in the grammar window.
Enter test cases in the examples window. Each test snippet appears as a single line, at first. Double-click on a test case to open a pop-up window that shows all of the details of the test case.
The result of parsing is shown in the parse window. If the parse is successful, the results are shown in gray color. Unsuccessful partial parses are shown in red. Hovering over a parse entity highlights the grammar rule and highlights the part of the test text that is constitutes the parsed entity.
Test the Grammar
Enter partial tests in the top-right window by clicking "Add".
Note that the parser defaults to using the first grammar rule as the top-level target. Parsing will fail if the top rule does not match the test case — in small test cases it might be necessary to insert sub-rule names as the first line of the grammar.
Run the Grammar / Parser
Ohm-JS creates a parser in Javascript.
To use the created parser, one needs to have access to the ohm library (e.g. via npm).
The Ohm-JS documentation explains how to use the parser in a web page or at the command line.
I choose to use the command line, via node.js, but Ohm-JS is certainly not restricted to being used in this manner.
My code for a full parser is:
// npm install ohm-js
const grammar = `
SM {
Main = StateMachine
StateMachine = NameSection InputSection OutputSection MachineSection
NameSection = "name" ":" Name
InputSection = "inputs" ":" InputPinNames
OutputSection = "outputs" ":" OutputPinNames
MachineSection = Header State+ Default Trailer
Header = "machine" MachineName ":"
Trailer = "end" "machine"
Default = "default" ":" Name
State = "state" StateName ":" EntrySection Transition*
EntrySection = "entry" ":" string
Transition = "on" Name ":" "next" Name
keyword = "machine" | "name" | "inputs" | "outputs" | "end" | "state" | "entry" | "on" | "next" | "default"
InputPinNames = nameList
OutputPinNames = nameList
MachineName = Name
StateName = Name
InputPinReference = Name
StateReference = Name
Name = ~keyword id
nameList = (~keyword id delim)+
id = firstId followId*
firstId = "A".."Z" | "a".."z" | "_"
followId = firstId
string = "\\"" stringChar* "\\""
stringChar =
escapedChar
| anyStringChar
escapedChar = "\\\\" any
anyStringChar = ~"\\"" any
delim = (" " | "\\t" | "\\n")+
}
`;
function parse (text) {
var ohm = require ('ohm-js');
var parser = ohm.grammar (grammar);
var cst = parser.match (text);
if (cst.succeeded ()) {
return {parser: parser, tree: cst};
} else {
console.log (parser.trace (text).toString ());
throw "Ohm matching failed";
}
}
var fs = require ('fs');
function getNamedFile (fname) {
if (fname === undefined || fname === null || fname === "-") {
return fs.readFileSync (0, 'utf-8');
} else {
return fs.readFileSync (fname, 'utf-8');
}
}
var text = getNamedFile("-");
var {parser, tree} = parse (text);
Running the parser consists of invoking it and supplying it with code to be parsed. I saved my test code in toggle.scl. I saved the the above parser code in sm.js. I invoked the parser using node at the command line:
> node sm <toggle.scl
Wirte the Code Emitter
When run, the Ohm parser parses the source code and returns a data structure — a CST (concrete syntax tree — a tree representing the actual source code that was parsed[4]).
One writes a set of rules — in Javascript, if using Ohm-JS — to transpile the CST into final output. The Ohm-JS documentation calls this "the semantics".
One creates a "semantics" object, names it, then adds transpilation rules to it.
You can add more than one set of rules to a semantics object. For example, one set of rules might check the types and declarations of all of the incoming source code, whereas another set of rules might be used transpile the (checked) CST into final code.
For purposes of this example, I show only the transpiler rules and leave out checking rules. I avoid such details to make this example simpler to comprehend.
The set of transpilation rules are included in the code base. I chose to call the transpilation rules "js()". The final code for the parser and transpiler is:
Ohm-JS creates a parser in Javascript.
To use the created parser, one needs to have access to the ohm library (e.g. via npm).
The Ohm-JS documentation explains how to use the parser in a web page or at the command line.
I choose to use the command line, via node.js, but Ohm-JS is certainly not restricted to being used in this manner.
My code for a full parser is:
// npm install ohm-js
const grammar = `
SM {
Main = StateMachine
StateMachine = NameSection InputSection OutputSection MachineSection
NameSection = "name" ":" Name
InputSection = "inputs" ":" InputPinNames
OutputSection = "outputs" ":" OutputPinNames
MachineSection = Header State+ Default Trailer
Header = "machine" MachineName ":"
Trailer = "end" "machine"
Default = "default" ":" Name
State = "state" StateName ":" EntrySection Transition*
EntrySection = "entry" ":" string
Transition = "on" Name ":" "next" Name
keyword = "machine" | "name" | "inputs" | "outputs" | "end" | "state" | "entry" | "on" | "next" | "default"
InputPinNames = nameList
OutputPinNames = nameList
MachineName = Name
StateName = Name
InputPinReference = Name
StateReference = Name
Name = ~keyword id
nameList = (~keyword id delim)+
id = firstId followId*
firstId = "A".."Z" | "a".."z" | "_"
followId = firstId
string = "\\"" stringChar* "\\""
stringChar =
escapedChar
| anyStringChar
escapedChar = "\\\\" any
anyStringChar = ~"\\"" any
delim = (" " | "\\t" | "\\n")+
}
`;
function parse (text) {
var ohm = require ('ohm-js');
var parser = ohm.grammar (grammar);
var cst = parser.match (text);
if (cst.succeeded ()) {
return {parser: parser, tree: cst};
} else {
console.log (parser.trace (text).toString ());
throw "Ohm matching failed";
}
}
var fs = require ('fs');
function getNamedFile (fname) {
if (fname === undefined || fname === null || fname === "-") {
return fs.readFileSync (0, 'utf-8');
} else {
return fs.readFileSync (fname, 'utf-8');
}
}
//////////// transpiler ////////
var nameCounter;
function createTranspiler (parser) {
var semantics = parser.createSemantics ();
nameCounter = 0;
semantics.addOperation (
"js",
{
Main : function (_1) { return _1.js (); }, // StateMachine
StateMachine : function (_1, _2, _3, _4) { // NameSection InputSection OutputSection MachineSection
var nameSection = _1.js ();
var inputSection = _2.js ();
var outputSection = _3.js ();
var machineSection = _4.js ();
return `
${inputSection}
${outputSection}
${machineSection}
`;
},
NameSection : function (_1, _2, _3) { return _3.js ().name; }, // "name" ":" Name
InputSection : function (_1, _2, _3) { return _3.js (); }, // "inputs" ":" InputPinNames
OutputSection : function (_1, _2, _3) { return _3.js (); }, // "outputs" ":" OutputPinNames
MachineSection : function (_1, _2s, _3, _4) { // Header State+ Default Trailer
var machineName = _1.js ();
var snippets = _2s.js ();
var defaultState = _3.js ();
var preamble = snippets.map (snippet => { return snippet.preamble; }).join ('\n');
var stateCode = snippets.map (snippet => { return snippet.step; }).join ('\n');
var entryCode = snippets.map (snippet => { return snippet.entry; }).join ('\n');
var smCode = `
${preamble}
function ${machineName} () {
this.state = ${defaultState};
this.enter = function (next_state) {
switch (next_state) {
${entryCode}
}
}
this.step = function (event) {
switch (this.state) {
${stateCode}
};
}
}
`;
return smCode;
},
Header : function (_1, _2, _3) { return _2.js (); }, // "machine" MachineName ":"
Trailer : function (_1, _2) {return "";}, // "end" "machine"
State : function (_1, _2, _3, _4, _5s) { // "state" StateName ":" EntrySection Transition*
var pair = _2.js ();
var name = pair.name;
var preamble = pair.preamble;
var entry = _4.js ();
var transitions = _5s.js ();
var stepcode = `
case ${name}:
switch (event.tag) {
${transitions}
};
break;
`;
var entrycode = `
case ${name}:
${entry}
this.state = ${name};
break;`;
return { preamble: preamble, step: stepcode, entry: entrycode, defaultState: "" };
},
EntrySection : function (_1, _2, _3) {return _3.js ()}, // "entry" ":" string
Transition : function (_1, _2, _3, _4, _5) { // "on" Name ":" "next" Name
var tagName = _2.js ().name;
var nextStateName = _5.js ().name;
var transitionCode = `
case ${tagName}:
this.enter (${nextStateName});
break;
`;
return transitionCode;
},
Default : function (_1 ,_2, _3) { // "default" ":" Name
var name = _3.js ().name;
return name;
},
keyword : function (_1) {return _1.js ()}, // "machine" | "name" | "inputs" | "outputs" | "end" | "state" | "entry" | "on" | "next" | "default"
InputPinNames : function (_1) {return _1.js ()}, // nameList
OutputPinNames : function (_1) {return _1.js ()}, // nameList
MachineName : function (_1) {return _1.js ().name}, // Name
StateName : function (_1) {return _1.js ()}, // Name
InputPinReference : function (_1) {return _1.js ().name}, // Name
StateReference : function (_1) {return _1.js ().name}, // Name
Name : function (_1) { // ~keyword id
var name = _1.js ();
nameCounter += 1;
var constant = `const ${name} = ${nameCounter};`;
return { preamble: constant, name: name };
},
nameList : function (_1s, _2s) { // (~keyword id delim)+
var consts = _1s.js ().map (name => {
nameCounter += 1;
return `const ${name} = ${nameCounter};`;
});
return consts.join ('\n');
},
id : function (_1, _2s) { // firstId followId*
var name = `${_1.js ()}${_2s.js ().join ('')}` ;
return name;
},
firstId : function (_1) {return _1.js ()}, // "A".."Z" | "a".."z" | "_"
followId : function (_1) {return _1.js ()}, // firstId
string : function (_1, _2s, _3) { return `${_2s.js ().join ('')}`; }, // "\\"" stringChar* "\\""
escapedChar : function (_1, _2) { return _2.js (); }, // "\\\\" any
anyStringChar : function (_1) {return _1.js ();}, // ~"\\"" any
delim : function (_1s) {return _1s.js ().join (''); }, // (" " | "\\t" | "\\n")+
_terminal: function () { return this.primitiveValue; }
});
return semantics;
}
////////////
var text = getNamedFile("-");
var {parser, tree} = parse (text);
var transpiler = createTranspiler (parser);
console.log (transpiler (tree).js ());
// boilerplate
console.log (`
function fire (output, value) {
console.log ("Fire called: " + this.toString () + " output:" + output.toString () + " value:" + value.toString ());
}
function send (component, tag, value) {
component.step ( {tag, value} );
}
function inject (component, event) {
component.step (event);
}
var top = new Toggle ();
inject (top, {tag: _in, value: true});
inject (top, {tag: _in, value: true});
inject (top, {tag: _in, value: true});
`);
Note that I added some boilerplate code at the end. This code is needed to make this simple example run.
Run the Transpiler
The transpiler is built at the command line using:
> node sm <toggle.scl >out.js
To run the transpiler, one needs to invoke the node interpreter:
> node out
As mentioned earlier, Ohm-JS is not restricted to being run from the command line and can run inside a web page.
Refer to the Ohm-JS documentation https://github.com/harc/ohm or to my essay https://computingsimplicity.neocities.org/blogs/OhmInSmallSteps.pdf.
Iterate
Once the SCL has been built for the test sample code, embellish the transpiler with more language constructs, recompile and re-run.
[1] PEG means Parsing Expression Grammars. PEGs are IMO, better than REGEXPs, and are just as accessible to programmers without any need for compiler theory. PEG libraries are available for many languages. The original PEG thesis can be found at https://bford.info/pub/lang/peg/
[2] Stack-based languages, are currently called "concatenative" languages. An early stack-based language is Forth. I first saw compiler technology using a stack-based language in S/SL and PT Pascal (see my list of References).
[3] PL means Programming Language.
[4] An AST — Abstract Syntax Tree — is a tree of the possible parses of all sources. The CST is a subset of all possible parses. We use the CST.