Multitasking Faking
Introduction
We examine how multitasking is implemented on a single CPU system.
This same strategy applies to multi-core systems (albeit, with more details).
Single CPU - Global Everything
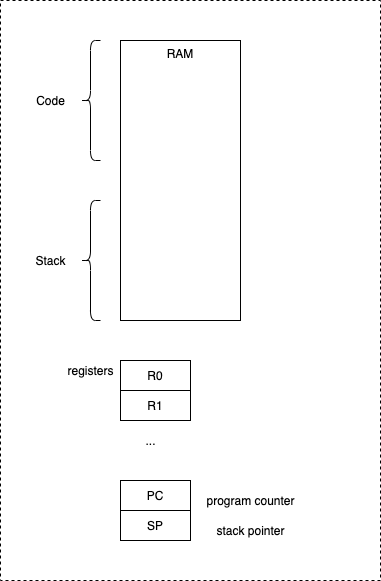
On a single CPU, hardware provides us with
- memory (RAM)
- registers.
Memory and registers are globals, shared by all functions on the CPU.
Notably, there are two most-interesting registers:
- PC - the program counter - memory address of the function (code) currently being executed.
- SP - the stack pointer - memory address of the top of the “stack”.
CONS, CAR and CDR
[You don’t need to understand Lisp for this, although, for convenience, I use Lisp-y terminology.]
A CDR is a pointer to the next cell.
A CAR is data.
A CONS is a cell containing one CAR and one CDR.
A CONS cell can be implemented (specified) as a user-defined data structure or a class.
Stack
The stack is simply an optimized list.
The stack is an array of CARs, with no CDRs.
There is no need to point to the next cell, since all cells are continguous (i.e. an array). Hence, the CDR is optimized-away.
Hardware implements access to the stack using a special register called SP.
There is typically only one SP in a CPU and it is shared (global) by all code1 on that CPU.
Globals
In a single CPU, all memory and all registers are global to all functions (code) on that CPU.
Synopsis - Faking Multitasking
We fake out multitasking by creating a component for each process, with its own virtual memory and virtual register set.
We call such components threads.
We use libraries, called operating systems, to help handle the repetitive, detailed work under-the-hood.
We supercede operating systems’ scheduling decisions when we use CALL and RETURN assembler instructions.
We treat all components as being synchronous.
Too Few CPUs - Faking Multitasking
We only need to fake multitasking when we have fewer CPUs than we have components (threads).
In the 1950’s, CPUs were expensive. We time-sliced CPUs to save money.
Today, CPU’s are cheap. IoT (internet of things) goes to the extreme of providing on CPU for each thread (one thread per device).
Faking Multitasking Threads
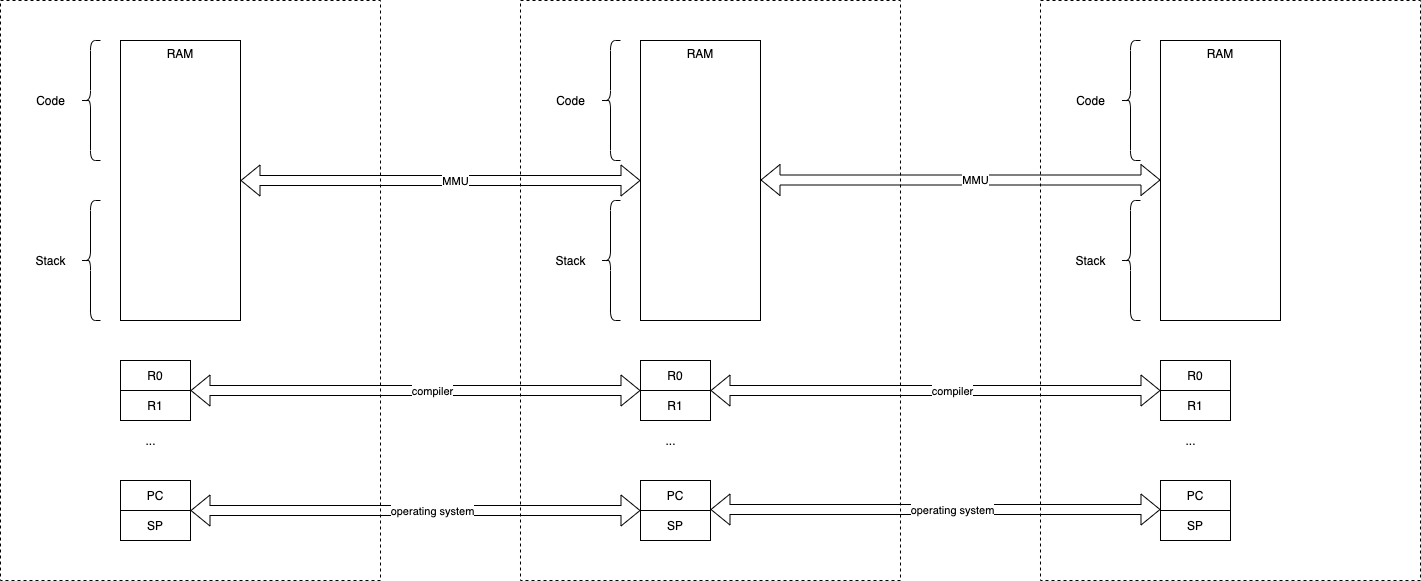
To fake out multitasking, most operating systems wrap all of the globals inside an envelope and create a fresh envelope for each process.
Operating systems tweak the MMU2 to fake out a fresh memory space for each process.
Operating systems tweak the PC3 register to fake out unique running functions for each process.
Operating systems tweak the SP4 register to fake out a unique stack for each process.
The SP is made to point to the memory space of the process, which is determined by the MMU, which is tweaked by the operating system to match each process.
Programmable Calculators
The current FP5 fad treats all computers as programmable calculators.
Computers are capable of being more than just programmable calculators. For example, computers can sequence the operation of devices.
The programmable-caculator fiction has some conveniences.
For example, this fiction allows the use of a notation called mathematics.
This notation relies on one feature - the feature of substituting one piece of notation for another, e.g. replacing one function by another function that has exactly the same input(s) and output(s)6.
This feature comes with some restrictions:
- side-effects are not allowed
- every function must return a value(s)
- when a function is invoked, the calling function schedules itself to sleep until the called function has finished its work and has returned a value(s). This is called synchronous operation.
The notation makes certain types of things hard to express, e.g.
- multitasking
- functions that run forever (for example servers)
- one-way functionality (also called history)7
- asynchronous operation (e.g. distributed processing, like internet, blockchain, p2p, etc.)
[Note that the notation called “mathematics” can express these things, but results in complicated expressions of these concepts that tend not to be popular. We teach hard realtime notation to 5-year-olds (e.g. piano lessons) but need university training to understand multitasking when expressed in mathematical terminology.]
Conflating Control Flow and Data
A computer deals with 2 concepts:
- memory
- control-flow.
One way to imagine these concepts is to think of asynchronous components that send messages8 to one another.
Each component has its own memory which is not shared with other components.
Unique memory is contained in each component.
A Dispatcher determines which component is allowed to run (i.e. gets control of the CPU and all of its globals).
Currently, we use various general-purpose programming languages to program the internals of components and use operating systems to dispatch components (which are called threads / processes).
Ad-Hoc Dispatch - CALL/RETURN
Currently, functions perform ad-hoc dispatch by calling other functions (e.g. using the built-in CALL and RETURN assembler instructions).
Functions perform a rendezvous-dance with callees and supercede dispatching decisions made by the operating system.
Operating systems are built to wrench dispatching control away from functions using preemption.
Rendezvous
Rendezvous is a subset of message-passing.
Rendezvous is a method for converting asynchronous processes into synchronous processes.
In a rendezvous, a component can send exactly one message.
The sending component must wait until the receiver accepts the message and sends back a completion event.
Rendezvous treats all message queues between components, as being 1 item in length.
Dispatcher
We fake out multitasking by providing a single routine which I call the dispatcher.
Each CPU is, in essence, its own dispatcher.
We need to provide explicit dispatchers only when we fake out multitasking.
Interpretation
A hardware CPU is an interpreter.
It is hard-wired to interpret assembly instructions.
In the simplest cases, i.e. without operating systems, CPUs interpret instructions for a single thread.
If more threads on a single CPU are needed, we add complexity by adding operating systems to fake out multitasking.
See Also
-
“All code” means any code, functional or procedural. ↩
-
MMU means Memory Management Unit. Sometimes a special IC or built into the CPU itself. ↩
-
PC means Program Counter (a register). ↩
-
SP means Stack Pointer (a register). ↩
-
FP means Functional Programming. ↩
-
This is called Referential Transparency in Computer Science. It used to be called pin-for-pin-compatibility by hardware designers (esp. when ICs were expensive and were pushed into sockets instead of being soldered into circuits). ↩
-
See “Order Out Of Chaos” by Ilya Prigogene to see why it is necessary to think in terms of one-way history. ↩
-
I believe that message sending needs to be structured to be useful, like Structured Programming, scoped variables instead of globals, etc. I discuss this elsewhere. ↩