PT Notes for Torlisp - Language Jam
Language Jam (langjam)
Theme
First Class Comments
Restrictions
48 hours to implement and document
My Approach
Goal
Executable diagrams
README.md
Sequence Diagram
Tools
- Ohm-JS
- SWIPL (PROLOG
- /bin/bash commands: cat, tsort, mv, sed, (and scripts)
2 Kinds of Diagrams
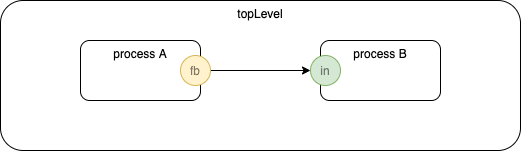
- Sequence diagram (Pert Chart) (boxes joined by arrows denoting ordering)
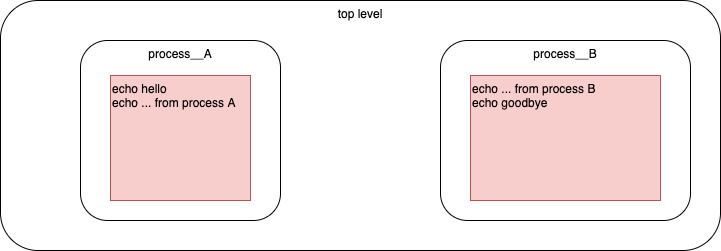
- Details diagram (snippets of /bin/bash code in red boxes)
Sequence Diagram
Details Diagram
Sequence Transpiler
5 Ohm-JS passes -> sort -> PROLOG -> JSON -> Ohm-JS to /bin/bash
Details Transpiler
6 Ohm-JS passes -> sort -> PROLOG -> JSON -> Ohm-JS to /bin/bash
Passes
Each pass consists of 2 specifications:
- grammar (*.ohm)
- action code (aka semantics) (*.glue)
Each pass augments the factbase (fb.pl), there is no need to remove1 facts.
Sequence Transpiler Passes
- compressed .drawio file -> uncompressed .XML
- normalize attributes (e.g. style=”…”)
- cull attributes, discard attributes that are concerned only with graphical representation (keep: value, source, target, edge, vertex, id, green, yellow, red)
- symbol table - map long id names to short id names (not strictly necessary, but aids human readability duing bootstrap)
- culled .XML -> factbase (fb.pl)
- sort - needed only to appease PROLOG (original PROLOG required that all clauses be grouped together, while modern PROLOG relaxes this constraint. The sort pass appeases original PROLOG.)
Details Transpiler Passes
- compressed .drawio file -> uncompressed .XML
- normalize attributes (e.g. style=”…”)
- cull attributes, discard attributes that are concerned only with graphical representation (keep: value, source, target, edge, vertex, id, green, yellow, red)
- symbol table - map long id names to short id names (not strictly necessary, but aids human readability duing bootstrap)
- culled .XML -> factbase (fb.pl)
- fold newlines, create one newline-less string for each snippet of code (helps sort)
- sort - needed only to appease PROLOG (original PROLOG required that all clauses be grouped together, while modern PROLOG relaxes this constraint. The sort pass appeases original PROLOG.)
Sequence JSON
{"diagram":"id1", "toplevelcomponent":"id4"}
{
"children": ["process A", "process B" ],
"connections": [
{
"name":"x2",
"source": {"component":"process A", "port":"fb"},
"target": {"component":"process B", "port":"in"}
}
],
"diagram":"id1",
"id":"id4",
"inputs": [],
"name":"topLevel",
"outputs": [],
"synccode":""
}
{
"children": [],
"connections": [],
"diagram":"id1",
"id":"id5",
"inputs": [],
"name":"process A",
"outputs": ["fb" ],
"synccode":""
}
{
"children": [],
"connections": [],
"diagram":"id1",
"id":"id6",
"inputs": ["in" ],
"name":"process B",
"outputs": [],
"synccode":""
}
Details JSON
{"diagram":"id1", "toplevelcomponent":"id4"}
{
"children": ["process A", "process__B" ],
"connections": [],
"diagram":"id1",
"id":"id4",
"inputs": [],
"name":"top level",
"outputs": [],
"synccode":""
}
{
"children": ["code1" ],
"connections": [],
"diagram":"id1",
"id":"id5",
"inputs": [],
"name":"process A",
"outputs": [],
"synccode":""
}
{
"children": [],
"connections": [],
"diagram":"id1",
"id":"id6",
"inputs": [],
"name":"code1",
"outputs": [],
"synccode":"@~@echo hello@~@echo ... from process A@~@"
}
{
"children": ["code2" ],
"connections": [],
"diagram":"id1",
"id":"id7",
"inputs": [],
"name":"process__B",
"outputs": [],
"synccode":""
}
{
"children": [],
"connections": [],
"diagram":"id1",
"id":"id8",
"inputs": [],
"name":"code2",
"outputs": [],
"synccode":"@~@echo ... from process B@~@echo goodbye@~@"
}
Relationship to Lisp
- PEG parsing <- generalization of Lisp macros
- PEG parsing in a separate pre-pass accomplishes the same result as hygenic macros, except with less complication (YMMV)
Fallout
- created ftranspile() and stranpsile() functions to abstract (hide) transpiler functionality
Continuing Work
- “eat your own dogfood” - compiled diagram of diagram compiler
- simplification of code
Github
Winners
PEG for Zodetrip
See Also
-
Removing facts is an optimization that is not needed on current hardware. Diagrams remain small, so runtime is imperceptable. Keeping facts allows for future flexibility (e.g. querying the fact base and making inferences that were not foreseen during original development). ↩