Class-Based Languages vs. Prototype-Based Languages
WIP
Lookup
The main difference between JavaScript and classless Lisp1 is the way that values are looked up.
To lookup a symbol, we start by looking at the own variables belonging to the symbol. The own slot contains a table that maps names to values.
In classless Lisp, a symbol value is looked-up once, with no iterations. Either the symbol has a named slot or it doesn’t.
In JavaScript, the lookup is an upward-tree-walk. If the named slot does not exist in an object’s own table, we try again to lookup the name in the object’s ancestor. This lookup process repeats until there is no ancestor.
[In class-based systems, including CLOS, the tree-walk is pre-optimized away during compilation. See below.]
Lookup Example
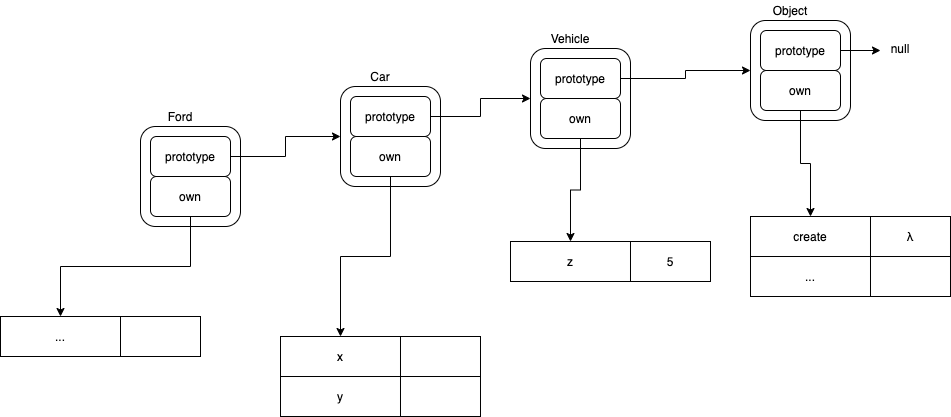
var a = new Ford ();
var b = a.z;
In JavaScript, b would be 300, since an ancestor of the Ford class (aka prototype) has a z field which contains the value 300.
Set
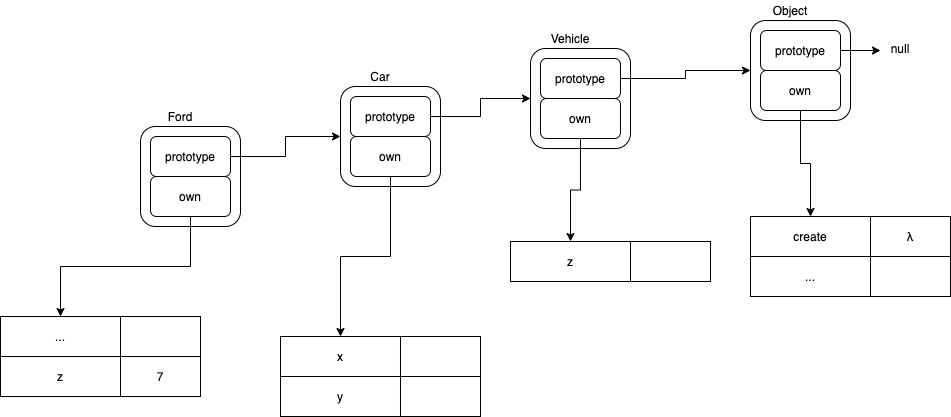
var a = new Ford ();
a.z = 7;
var b = a.z;
In JavaScript, the second line causes a new slot, called z to be created in the Ford class (prototype), then 7 is assigned to that new field.
In JavaScript, if the field already exists in Ford, the field is simply overwritten and not re-created.
Optimization
JavaScript performs copy on write when writing to fields of an object.
In JavaScript, the z slot is created only if required. This happens at runtime.
In class-based systems, copy on write is pre-optimized by the compiler2. The compiled object always contains a unique z slot (after compilation).
In JavaScript, if an object does not contain a slot with a given name, the system looks up the value in the object’s ancestors. This happens at runtime.
In classless Lisp, there is no lookup. Either the slot exists or it doesn’t.
In class-based systems, the lookup is pre-optimized-away. All objects contain slots corresponding to their ancestors’ slots.
There is a trade-off. The JavaScript method is simpler but uses CPU time for lookups at runtime.
Class-based systems optimize for final app speed at the expense of doing more work during compilation. Class-based systems use up CPU time, just like prototype-based-systems, but class-based systems amortize the cost over the number of times that the final app is executed.
Class-based systems are less flexible than prototype-based systems, because the language needs to be constrained to help the compiler/optimizer figure things out.
In class-based languages, the programmer is stuck with slot-composition rules set by the language designer.
In prototype-based languages the programmer is free(er) to choose the rules and patterns that will be used.
Programming
Both methods have a place in programming.
Flexibility
Prototype-based systems are more flexible and are suited to Software Architecture and initial Engineering.
Class-based systems are less flexible, but, (usually) produce more efficient code (speed) and are suited to Production Engineering.
The Continuum
I see programming as a continuum of activities.
At one end of the continuum, Design is the most important consideration.
At the other end of the continuum, Production Engineering is the most important consideration.
The ideal situation would be to allow automated mapping from prototype-based designs to Production Engineered products.
A mid-level ideal would be to have design rules - like lint - report if un-compilable uses of prototypes exist in the code.
At present, we are stuck with a low-level approach.
All Designs are done with Production Engineering languages and concepts. The Designer must specify all Engineering details, which constrains the thought-processes during Design.
[Optmization, e.g. compilation, also affects grain-size for scalability.]
Design vs. Production Engineering
Theorists tend to treat Design as a secondary issue.
People like Jef Raskin and Bret Victor point out that Design is important, too.
Early lisp, and BASIC, were dynamic languages that emphasized Design (this used to be called “Rapid Prototyping”).
The invention of JavaScript is a tell that programming has several orthogonal dimensions.
Jef Raskin’s book “The Humane Interface” contributed to the science of UX Design.
Lisp explored the continuum between Design and Production Engineering, with features like gradual typing (after-the-fact typing, DECLARE), fast-calls (which is a pre-cursor to JIT), garbage collection, REPLs, etc.
Inheritance
In programming, one of the big wins is DRY - Don’t Repeat Yourself.
Humans don’t like to repeat themselves.
In fact, we have found that, as we increase our understanding of a problem, we see patterns of similarities in the problem and we try to collapse such similarities together. We have learned that, if the similarities are not collapsed, then updates require “more work” to perform and leave the potential for leaving dangling un-updated code blobs that result in mysterious bugs.
Class-based inheritance is a (manual) way to get programmers to expend brain-power on pointing out similarities between similar data structures.
Instead of having the compiler automatically figure out the similarities in a Design, with something like diff, the programmer must appease the compiler by explicitly declaring such similarities using text-based inheritance syntax. Currently, our programming languages expect programmers to help compilers figure this stuff out.
I haven’t explored it, but NiCad sounds like a step in the direction of automating similarity-detection.
See Also
Table of Contents
Blog
Videos
References
Books
-
Early Lisps did not have classes. The class system is written in Lisp and is called CLOS. This is similar to the way the JavaScript evolved. JavaScript originally only had prototypes, not classes. Later, class systems were written in JavaScript and, then, classes were promoted to the ESx standard. Classes are an optimization (“static language” means pre-optimized, “dynamic language” means ) ↩
-
Compilers are just programs - apps. We run compilers before shipping a product in the hope that the compiler will optimize the product and make it run “more efficiently” on customers’ machines (reducing the customers’ cost, amortizing the cost of running the optimizer app during product development). ↩