On Concurrency
On Concurrency
Synopsis
- Concurrency Is Not Parallelism
- Blocking
- Parameters vs. Ports
- Dependencies
Concurrency Is Not Parallelism
Concurrency is a healthy lifestyle.
Parallelism is a greasy hamburger.
Concurrency is a paradigm.
Parallelism is an optimization.
Programs written in the concurrent paradigm need not be parallel.
Parallel programs must be concurrent.
Concurrent programs must have no dependencies on one another
- data dependencies, nor,
- control flow dependencies.
Parameters vs. Ports
Briefly …
f(a,b,c) -> ...- one parameter destructured into 3 parts
- what we call parameters are actually sub-ports
f (...) -> x,y,z- one return value, destructured into 3 parts.
- blocking
f (a,b,c) -> ...
f (a,b,c) -> ... implies that a and b and c arrive at the same time. I call that one (1) port.
(a,b,c) is an input port.
In fact, that is how current-day compilers implement parameters.
All data is pushed onto the stack and sent to the callee as a single block.
The callee destructures the data on the port into separate parameters.
f (...) -> x, y, z
The return value represents one (1) output port.
The caller destructures the return value into separate data slots.
f (a, b, c) -> x, y, z
F is a component with exactly one (1) input port and one (1) output port.
This notation does not allow for multiple (or zero) ports arriving / sent at different times.

f (a, b, c) (d, e) (g, h) -> (x, y, z) (u, w) (p q)
Three (3) input ports, three (3) output ports.
Ports can fire (arrive, be sent) at different times.
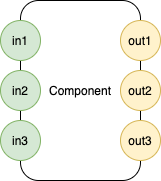
f -> (x, y, z) (u, w) (p q)
Zero (0) input ports, three (3) output ports.
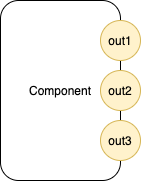
f (a, b, c) (d, e) (g, h) ->
Three (3) input ports, zero (0) output ports.
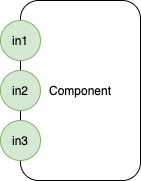
f
Zero (0) input ports, zero (0) output ports.
Daemon, server.

Dependencies
- Concurrency Is Not Parallelism
- Programs that are concurrent have no dependencies on one another.
- Life is filled with concurrency.
- E.G. This apple is not dependent on that ball. If you cut the apple, you do not expect that ball to begin moving.
- CALL / RETURN
- CALL/RETURN creates an implicit dependency chain that uses a global, shared variable (The Stack).
f (a, b, c) -> ...- means that
a,b, and,care dependent on one another - they must arrive at the same time1
- means that
Blocking
- CALL/RETURN
- Caller blocks (suspends operation) until callee returns
- Does the caller “know” whether the callee will, also, block? In general, no.
Blocking is thought to be the domain of operating systems, but blocking is also controlled by CALL/RETURN.
Blocking does not obey locality-of-reference. Sometimes blocking is performed by the operating system, sometimes, blocking is performed by function calls.
Epicycle - Preemption
Preemption was invented as a way for the operating system to yank control away from functions.
Preemption has resulted in epicycles and mysterious bugs, e.g. Mars Pathfinder disaster.
Epicycle - Loop (Recursion)
Early attempts at creating programming languages involved knee-jerk constructs like Loop (later refined to recursion).
Supporting Loop required the creation of the epicycle called preemption.
Truly concurrent, non-inter-dependent, software Components do not use Loop.
If a Component really, really wants to Loop, it can send itself a message.
Loop (recursion) is valid and usable on systems that share memory, e.g. single-CPU systems (extended to multi-core systems). One would not send a stack along a wire to another processor, hence, programming languages that have built-in Loop (and recursion) are not natural ways to describe distributed systems. The CALL/RETURN paradigm has a natural limitation that makes it hard to use in distributed situations2.
Synchronization
Synchronization is the exception not the rule.
Currently, PLs make synchronization the rule, not the exception.
This led to the creation of the epicycle3 called operating systems.
Explicit synchronization is well-understood, e.g.
- hardware design
- network protocols
Most real problems do not require synchronization.
Time
Synchronization is a function of time and history.
Removing time and history from a problem - a notation (model) describing a problem - is a useful approach, but has limits.
Such - time-removed - notation cannot describe time-based sequencing, except through the use of tricks and warps to the notation, e.g. clever, PhD-level, “complicated” epicycles.
Such cleverness hides higher-level layers of description.
Sequencers
In the cases where a problem needs to be sequenced in time, one builds a sequencer.
Examples
- DAWs (Digital Audio Workstation), e.g. ProTools®, Logic®, etc.
- Movie production, e.g. iMovie®
- machine control, robotics
Single Point of Failure
The problem of building a sequencer can lead to sub-problems, like
- single point of failure.
This problem is being attacked with research on distributed systems, p2p, etc.
In my opinion, the solution lies in considering the system at a higher level.
Synchronization might be designed-in at a high level, not at the low level.
IOW: working with only low-level, pervasive synchronization keeps one too busy devising tricks and escapes instead of viewing the larger picture 4
Business Hierarchy
Businesses are arranged in a top-down hierarchical manner.
Businesses appear to have a single point of failure - the CEO.
If the CEO of a business is changed, the business does not necessarily fail.
Why?
Ethernet
Ethernet is a solution to a problem which rarely needs synchronization.
Synchronization is so rare, that it is completely left out of consideration.
In the rare case that multiple Components collide and try to use the same resource at the same time (e.g. writing data onto a data bus), the Components do not synchronize - they simply back off for random amounts of time.
Obviously, this non-synchronization algorithm works. We use it daily.
Internet
Asynchronous clients and servers.
Current, synchronous, programming languages do not serve this domain well.
HTML and JavaScript were invented to describe internet apps.
HTML and JavaScript are but low-level (assembly) languages for describing this domain.
Bloatware
Tunney’s Sector Lisp and BLC are examples of the beautiful simplicity of the functional paradigm.
Tunney’s Garbage Collector5 is 40 bytes ([sic], bytes, not K, not M, not G).
Sector Lisp started out as a project whose goal was smallness (in bytes, in size) of executable, but, involved preening the basic paradigm and removing cruft.
When we corrupt this simple paradigm, the result is bloatware.
Corruption often involves mid-1900s biases, like conserving CPU time6 and conserving memory7. Attention to “efficiency” has resulted in premature optimization.
Electronic computers are inherently based on CPUs and mutation, hence, the very-pure functional paradigm cannot describe (model) all of what electronic computers can do.
The functional paradigm is a useful paradigm for describing a subset of what electronic computers can do, but it behooves one to understand the limitations of this paradigm.
Tells that the functional paradigm is being stretched beyond its natural limits:
- The invention of JavaScript callbacks.
- Use of Continuation Passing Style (CPS). CPS is the new GOTO. CPS leads to write-only code.
- The invention of Operating Systems.
- Only a few apps require full-blown preemption and operating-system-ness, e.g. Windows®, MacOS®, Linux
- Full preemption is really only needed during development to trap runaway, buggy programs-under-development. We use full-preemption as a crutch to allow us to ship runaway, buggy programs-under-development to customers.
- Synchrony. We, humans, are used to asynchronous things - we experience asynchrony and non-dependency every day in our lives. By inserting pervasive-synchrony-under-the-hood, we change the rules and have to learn how to deal with such things and to un-learn all of our experience with asynchronous things.
Games
Early games eschewed bloatware.
A Loop consisted of a simple branch+label.
Mbytes of O/S bloatware was not needed to implement Loop.
Scanning hardware devices, like joysticks, did not need Mbytes of O/S bloatware.
Games use mutation.
Programmers can try to push mutation aside, but, this results in bloatware.
Plumbing Notations Together
Functional parts of a program should be implemented in the functional domain.
Non-functional parts of a program, like mutation, should be implemented in some other domain.
Programmers need a way to plumb notations together to produce systems, not a way to express everything in only a single notation.
Electronics engineers figured this out.
Electronics engineers work with oxides. On top of this, they layer a notation called transistors. On top of this notation, they layer another notation called chips (VLSI, epoxy, pins). On top of this notation, there is another layer called assembler. On top of this notation, there is a notation called programming language(s). On top of this notation, there are signatures and implementations, etc.
It works going in the other direction, too. Oxides are built out of molecules. Molecules are built out of atoms. Atoms are not atomic, but, are built out of sub-atomic particles, etc.
Chips are asynchronous.
Inner Concurrency
Instead of Operating Systems calling functions, functions might have concurrency inside them.
[I’m currently working on presenting this concept. I call it ė.]
See Also
CALL/RETURN Spaghetti - my view on breaking implicit dependencies
Table of Contents as of Dec. 1, 2021
Blog
Videos
References
Books
-
This is a useful sub-class of problems, but, this is only a single sub-class. ↩
-
It has been done, e.g. with epicycles like RPC (Remote Procedure Call), but, it ain’t natural. This is a tell that switching to another notation is in order. ↩
-
Bloatware. ↩
-
And, once that has been viewed, stepping back and viewing the larger picture of the larger picture. Ad infinitum. ↩
-
Tunney’s GC is different from McCarthy’s original GC. Tunney’s is even more-functional. ↩
-
A.K.A. Time-Sharing. ↩
-
A.K.A. mutation and random access. ↩