Small Example of Interpreting and Compiling
Introduction
This note shows a very small example of using Ohm-JS to build an interpreter and a transpiler.
Steps
I suggest a sequence of 4 steps for producing a transpiler:
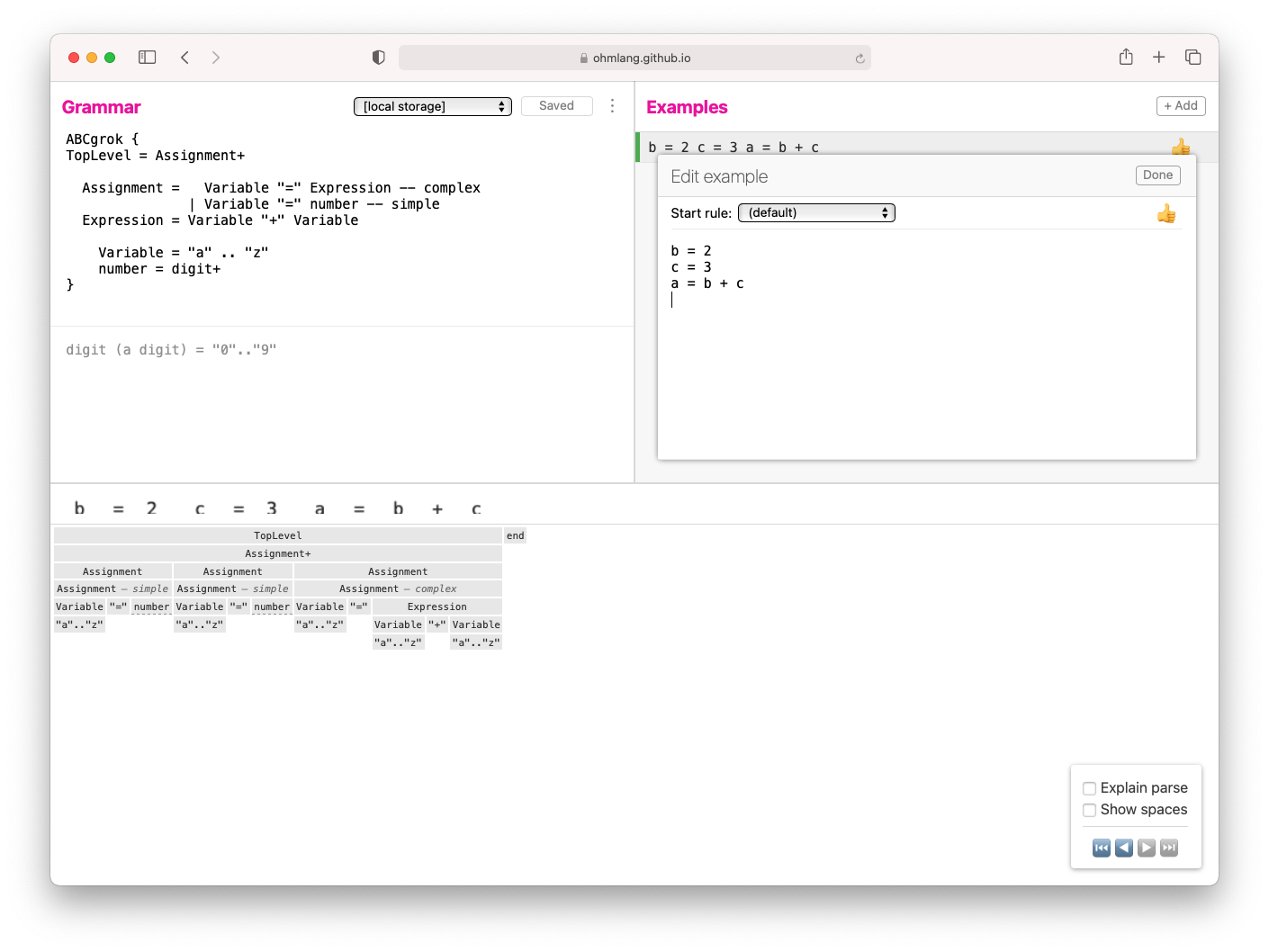
- Write and debug the grammar using Ohm-Editor.
- Build the Ohm-JS support code around the grammar. Test that it works.
- Build the interpreter.
- Modify the interpreter to turn it into a transpiler.
This note shows these 4 steps.
Transpiler / Compiler
I use the words transpiler and compiler interchangeably.
Typically, a compiler is thought to compile a source language into assembler.
I try to use the word transpiler when I am talking about compiling a source language into HLL assembler, like Common Lisp, JavaScript, etc1.
The task of building a transpiler is the same as building a compiler, but the details are different.
Ohm-JS
Ohm-JS is a PEG parser application that
- provides separation of concerns (grammar and semantics are specified separately, whereas most PEG ports spec the semantics directly into the grammar), and,
- provides an IDE for grammars (aka Ohm-Editor), making grammar development/testing simple.
The ABC Language
The ABC “language” allows:
- only single-letter variable names
- one operator
+which must refer to variables only (not numbers/integers) - assignment of integers to variables
- assignment of expressions to variables.
I hope that these severe simplifications make the underlying interpreter/transpiler simple to understand.
I believe that the underlying code can be easily extended to accept a larger input language.
Source Example - ABC
b = 2
c = 3
a = b + c
Step 1 - Grammar Development
Step 2 - Scaffolding
Step 2.1 - Roughing In The Action Code (Semantics)
Create a JS object with one named function property for each rule in the grammar.
The property names must match exactly with the names of the grammar rules.
Each function has parameters that name the sub-matches of a given rule.
Each function must have exactly the same number of parameters as there are sub-matches in the corresponding grammar rules.
The parameter names do not matter, but it is a good idea to make the names meaningful.
I use the prefix “k” to mean a constant string, called a terminal in Ohm-JS-ese.
Rules that have multiple branches with differing sub-matches must be marked by “– name” in the grammar. Such functions are written as function_name in the supporting JS code. Our example contains one such multi-branch rule - Assignment.2
exports.roughInSemantics = {
TopLevel: function (assignments) {
},
Assignment_simple: function (v, keq, n) {
},
Assignment_complex: function (v, keq, expr) {
},
Expression: function (v1, kplus, v2) {
},
Variable: function (c) {
},
number: function (ds) {
}
};
Step 2.2 - The Other Stuff
The grammar and the semantics need to be wrapped with boilerplate JS code.
I chose to put the grammar inline and the action code in a separate file. It doesn’t matter how the code is structured, as long as all of the code is seen by the JS compiler.
I chose to use node.js for this example, but a .html version of the code could also be constructed. In fact, Ohm-JS makes it easy to create grammars and compilers in webpages. See the Ohm-JS documentation for further details.
We need to bring in the libraries:
- ohm-js, and,
- fs.
We need to supply
-
the grammar
-
the action code (aka semantics)
-
test program source code.
First, we let Ohm-JS build a CST3 by parsing the test program source.
If that operation (the parse) succeeds, we hang various bits of action code (aka semantics) onto the CST generated by Ohm-JS.
In subsequent steps, we will hang an interpreter and a transpiler onto the generated CST. We will ask Ohm-JS to walk the parse tree and invoke our action code (aka semantics) during the tree-walk.
The rest of the source code for this step (2) is shown below:
'use strict'
var ohm = require('ohm-js');
var fs = require('fs');
var semanticsCode = require('./abcSemanticsRoughIn.js');
var source = fs.readFileSync ('test.abc', 'utf-8');
var grammar = `
ABCgrok {
TopLevel = Assignment+
Assignment = Variable "=" Expression -- complex
| Variable "=" number -- simple
Expression = Variable "+" Variable
Variable = "a" .. "z"
number = digit+
}
`;
function main () {
let parser = ohm.grammar (grammar);
let cst = parser.match (source);
if (cst.succeeded ()) {
let cstSemantics = parser.createSemantics ();
cstSemantics.addOperation ('roughIn', semanticsCode.roughInSemantics);
} else {
console.log (parser.trace (source).toString ());
throw ("grammar error :");
}
}
main ();
To run this second step, use the bash script:
./run2.bash
Step 3 - Interpreter
The interpreter executes ABC operations as the parse tree is walked.
Simple assignment statements, like
b = 2
fetch the variable name (b in this case), fetch the RHS value (2 in this case) and then put the fetche value into the symbol table under the fetched name.
A VM-based interpreter would create a stack data structure and would leave the fetched value on the stack.
The TopLevel function simply returns the whole symbol table, in this case. This is a convenient operation in JavaScript and might be implemented differently if another underlying language were used.
The tree walking is performed by calling the interpret() function on matching nodes.
exports.interpret = {
TopLevel: function (assignments) {
var dontcare = assignments.interpret ();
return symbolTable.symbolTable;
},
Assignment_simple: function (v, keq, n) {
var name = v.interpret ();
var value = n.interpret ();
symbolTable.symbolTable[name] = value;
},
Assignment_complex: function (v, keq, expr) {
let value = expr.interpret ();
symbolTable.symbolTable[v.interpret ()] = value;
},
Expression: function (v1, kplus, v2) {
let name1 = v1.interpret ();
let name2 = v2.interpret ();
let value1 = symbolTable.symbolTable [name1];
let value2 = symbolTable.symbolTable [name2];
return value1 + value2;
},
Variable: function (c) {
return this.sourceString;
},
number: function (ds) {
return parseInt (this.sourceString);
}
};
To run this (third) step use the bash script
/run3.bash
You should see
{ interpreted: { b: 2, c: 3, a: 5 } }
Step 4 - Transpiler
The transpiler (aka compiler) uses the same parse tree as in step 3, but performs different actions.
In this case, the TopLevel returns a string of JS code.
The transpiler converts ABC statements into JS statements. It should be obvious how to change this code to return a string of Python, WASM, etc. code.4
In this case, each action creates a string of code (JS code in this case). I used JS template strings as a convenience.
Each return statement returns a string.
The TopLevel function receives an array of strings (due to the + suffix operator in the grammar). The strings in this array are glued together into one large string (using the .join() JS method) and returned.
exports.transpile = {
TopLevel: function (assignments) {
var finalString = assignments.transpile ().join ('\n');
return finalString;
},
Assignment_simple: function (v, keq, n) {
var name = v.transpile ();
var value = n.transpile ();
return `var ${name} = ${value};`;
},
Assignment_complex: function (v, keq, expr) {
var name = v.transpile ();
var value = expr.transpile ();
return `var ${name} = ${value};`;
},
Expression: function (v1, kplus, v2) {
let name1 = v1.transpile ();
let name2 = v2.transpile ();
return `${name1} + ${name2}`;
},
Variable: function (c) {
return this.sourceString;
},
number: function (ds) {
return this.sourceString;
}
};
To run this (third) step use the bash script
./run4.bash
You should see (interpreted and transpiled code)
{ b: 2, c: 3, a: 5 }
var b = 2;
var c = 3;
var a = b + c;
Appendix Github
Appendix Ohm-JS
Appendix Ohm-Editor
Appendix See Also
Table of Contents
Blog
Videos
References
-
A “good” HLL assembler is a language that has little syntax, is mostly expression-based, doesn’t insist on declaration-before-use and so on. I.E. a “good” assembler language is machine-readable/writable but might not be very human-readable. The emphasis is on features that aid machine reading and writing. Human-readability is secondary. ↩
-
In fact, Assignment could easily be rewritten to have only one branch. I have left it as it is for expository purposes. Collapsing Assignment down to a single branch is left as an exercise to the reader. ↩
-
A CST is a Concrete Syntax Tree. It is, essentially, an AST (Abstract Syntax Tree) for the grammar, pruned down to only the nodes that are matched in the input test program. ↩
-
See below for examples of emitting WASM, Python, JS and Lisp for a more interesting example language (the arithmetic language in the Ohm-JS example set). ↩